由于Spark在使用JDBC方式讀取關(guān)系型模型數(shù)據(jù)的時候,默認采用單線程任務(wù)執(zhí)行。在數(shù)據(jù)量較大時,經(jīng)常發(fā)現(xiàn)內(nèi)存溢出、性能低的問題。在擴大內(nèi)存讀取后進行重分區(qū),又會消耗時間,浪費資源。
因此,開發(fā)并發(fā)讀取關(guān)系型模型數(shù)據(jù),可以有效提高任務(wù)處理并發(fā)度,減少單個任務(wù)的數(shù)據(jù)處理量,進而提升處理效率。
分布式并發(fā)處理優(yōu)化
(一)總體思路
關(guān)系型模型并發(fā)讀取首先要選取分區(qū)字段,按照字段類型和分區(qū)個數(shù)確定并發(fā)分區(qū)間隔的key值。假設(shè)key值可以將模型數(shù)據(jù)均勻劃分成多個邏輯分區(qū),根據(jù)key值構(gòu)成查詢條件將模型數(shù)據(jù)進行并發(fā)讀取。其中的關(guān)鍵點包括:
1、分區(qū)字段的選取規(guī)則
(a)初步確定模型中第一個字符或者數(shù)值型字段。
2、分區(qū)個數(shù)
(a)給出默認分區(qū)個數(shù),測試讀寫后按照1000w數(shù)據(jù)量給出建議的資源配比和默認分區(qū)個數(shù)。
(b)允許用戶進行自定義配置。
3、靜態(tài)分區(qū)策略
(a)數(shù)值型:轉(zhuǎn)換成字符并逆序,按照數(shù)值位取值的字符范圍和分區(qū)個數(shù)確定并發(fā)分區(qū)間隔的key值,進行多分區(qū)構(gòu)造。
(b)字符型:逆序后按照單字符取值范圍和分區(qū)個數(shù)確定并發(fā)分區(qū)間隔的key值,進行多分區(qū)構(gòu)造。
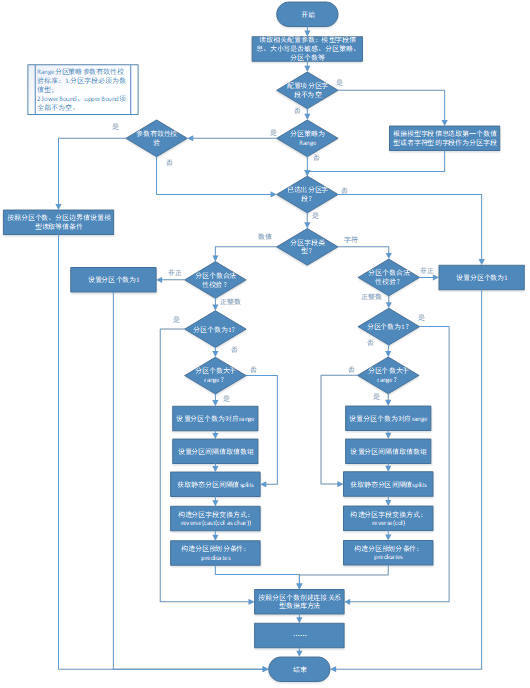
(二)總體處理流程
總體處理流程如圖所示:
(三)閾值范圍并發(fā)讀取
閾值范圍并發(fā)讀取適合分區(qū)字段為數(shù)值類型的模型。
關(guān)鍵參數(shù):
partitionColumn:分區(qū)字段名稱
lowerBound:取值下限
upperBound:取值上限
numPartitions:分區(qū)個數(shù)
(四)默認并發(fā)讀取
默認并發(fā)讀取適應(yīng)于字符和數(shù)值類型的分區(qū)字段,按照類型的取值范圍獲取近似均分的過濾條件,將數(shù)據(jù)按照條件分配到不同的邏輯分區(qū)中,并以并發(fā)執(zhí)行來提升數(shù)據(jù)讀取效率。
1、模型并發(fā)讀取
模型并發(fā)讀取設(shè)計按照分區(qū)個數(shù)不同采用不同的接口調(diào)用方式。
?分區(qū)個數(shù)為1
val url = "jdbc:mysql://host:3306/test"
val prop = new java.util.Properties
prop.setProperty("user", "***")
prop.setProperty("password", "***")
prop.setProperty("driver", "com.mysql.jdbc.Driver")
val df = spark.sqlContext.read.jdbc(url,"tname",prop)
url為數(shù)據(jù)庫連接串信息。
tname為查詢的表名,也支持查詢條件,形如:
(select * from ronghe_mysql_bigint_50wwhere cast(RY_YGGH as UNSIGNED) > 250000)tmp
prop為數(shù)據(jù)庫連接信息、用戶名、密碼、driver等配置信息。
?分區(qū)個數(shù)大于1
val url = "jdbc:mysql://host:3306/test"
val prop = new java.util.Properties
prop.setProperty("user", "***")
prop.setProperty("password", "***")
prop.setProperty("driver", "com.mysql.jdbc.Driver")
val df = spark.sqlContext.read.jdbc(url,"tname",predicates,prop)
多分區(qū)并發(fā)讀取比分區(qū)個數(shù)為1的參數(shù)增加了分區(qū)預(yù)劃分條件。
其中,predicates為分區(qū)預(yù)劃分條件,Array[String],讀取時按照每個元素內(nèi)容過濾數(shù)據(jù)。
2、分區(qū)預(yù)劃分條件
分區(qū)預(yù)劃分條件是由多個條件構(gòu)成的字符串數(shù)據(jù)。
val predicates = Array[String](
" cols < '3'",
" cols >= '3' and cols <'6'",
" cols >= '6'
)
分區(qū)預(yù)劃分條件包括分區(qū)條件列和比對值。分區(qū)條件值由選取的分區(qū)字段及其操作構(gòu)成,比對值即為靜態(tài)分區(qū)間隔值。考慮到有序數(shù)值型、字符型在業(yè)務(wù)場景中使用一般高位相似低位差異明顯,因此對分區(qū)字段進行逆序處理。
假設(shè)分區(qū)字段為splitCol。
splitCol為數(shù)值類型時:分區(qū)條件列cols 為reverse(cast(splitColas char))。
splitCol為字符類型時:分區(qū)條件列cols 為reverse(splitCol)。
假設(shè)分區(qū)間隔值為splitKeys(Array[String]),長度為L。對比值按照左閉右開的方式構(gòu)造。
第一個條件為cols < splitKeys(0);
第二個條件為cols >= splitKeys(0) and cols < splitKeys(1);
第i個條件為cols >= splitKeys(i-2)and cols < splitKeys(i-1);
最后一個條件為cols >= splitKeys(L-1)。
3、分區(qū)個數(shù)
模型并發(fā)讀取設(shè)計,按照四位字符來表示分區(qū)間隔值。那么,可表示的值范圍即為每位可取的值個數(shù)的四次方。
設(shè)定字符每位可取64個,數(shù)字可取的值個數(shù)10,即支持的最大分區(qū)個數(shù)(range):字符型(64的4次方)、數(shù)值型(10000)。
4、靜態(tài)分區(qū)間隔值獲取
實現(xiàn)思路
按照字段類型的字符范圍找到分區(qū)間隔值,即找到間隔值所表示范圍的近似均分位置點。
假定分區(qū)間隔值使用四位字符表示。(設(shè)N個分區(qū))
數(shù)字類型字符間隔值尋找思路:
(1)數(shù)字取值[0,9](暫不考慮小數(shù)點,按位將被分到小于0對應(yīng)的分區(qū)),表示范圍:1, 2, 3,……,9998,9999。
(2)找到每個分片的大小范圍S,表示范圍個數(shù)除以分區(qū)個數(shù)(10^4/(N-1))。
(3)S-1,2S-1,3S-1,……,(N-1)*S-1即為可以將四位數(shù)均分的間隔值。
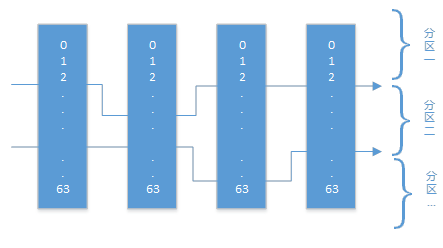
字符類型間隔值尋找思路(取值范圍64個字符,優(yōu)化算法):
(1)按照常用程度,將間隔值每位字符取值范圍確定為:Array('.', '0', '1', '2', '3','4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J','K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z','a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p','q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '~')
(2)不常用字符將被歸到最臨近的一個分區(qū),中文字符將被歸到最后一個分區(qū),避免不常用字符的獨占一個分區(qū)情況,以減少對資源的消耗。
(3)找到每個分段的大小范圍S,表示范圍個數(shù)除以分區(qū)個數(shù)(64^4/(N-1))
(4)同數(shù)字字符間隔值,將字符間隔值理解成64進制的數(shù)字(可以采用移位運算快速獲取),那么S-1,2S-1,3S-1,……,(N-1)*S-1就是將四位字符近似均分的數(shù)字,每位對應(yīng)的字符間隔值數(shù)組中的字符構(gòu)成的字符串即為間隔值。
for (j <- 1 to digitsNum) {
tmp(digitsNum - j) = charactors(keyInt & (charLength - 1))
keyInt >>= 6
}
字符類型間隔值尋找思路(取值范圍任意個字符,通用算法):
與字符類型字符間隔值總體尋找思路一致,但不受取值范圍個數(shù)的限制。
(1)按照常用程度,將間隔值每位字符取值范圍確定為Array(……),元素個數(shù)為m。
(2)不常用字符將被歸到最臨近的一個分區(qū),中文字符將被歸到最后一個分區(qū),避免不常用字符的獨占一個分區(qū)情況,以減少對資源的消耗。
(3)找到每個分段的大小范圍S,表示范圍個數(shù)除以分區(qū)個數(shù)(m^4/(N-1))。
(4)同數(shù)字字符間隔值,將字符間隔值理解成m進制的數(shù)字,那么S-1,2S-1,3S-1,……,(N-1)*S-1就是將四位字符近似均分的數(shù)字,這些數(shù)字對應(yīng)的字符串即為均分字符范圍的間隔值(數(shù)字每一位對應(yīng)的字符間隔值數(shù)組中的字符構(gòu)成的字符串即為間隔值)。
十進制轉(zhuǎn)為m進制,以十進制數(shù)keyInt為例,tmp為轉(zhuǎn)換后結(jié)果數(shù)組:digitsNum為表示位數(shù)4。
for (j <- 1 to digitsNum) {
tmp(digitsNum - j) = charactors(keyInt % m)
keyInt = math.floor(keyInt / m).toInt
}
測試結(jié)果
在數(shù)據(jù)資產(chǎn)平臺中,以50萬、1000萬的數(shù)據(jù)進行同步性能測試,測試結(jié)果如下表:
總結(jié)與展望
按照分區(qū)字段并發(fā)讀取數(shù)據(jù)進行處理能夠有效提升數(shù)據(jù)的處理能力,但受分區(qū)字段取值范圍、數(shù)據(jù)分布情況的影響,效果不盡相同,后續(xù)將對分區(qū)策略進行持續(xù)優(yōu)化,以達到適應(yīng)各種業(yè)務(wù)場景的性能要求。





























量評估報告合規(guī)審核")
據(jù)中臺,還需要做數(shù)據(jù)治理嗎?")
備智能運維檢修方案—驅(qū)動設(shè)備運檢業(yè)務(wù)效率躍遷")



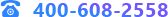

 Tempo商業(yè)智能平臺
Tempo商業(yè)智能平臺 Tempo人工智能平臺
Tempo人工智能平臺 Tempo數(shù)據(jù)工廠平臺
Tempo數(shù)據(jù)工廠平臺 Tempo指標平臺
Tempo指標平臺 Tempo數(shù)據(jù)治理平臺
Tempo數(shù)據(jù)治理平臺 Tempo主數(shù)據(jù)管理平臺
Tempo主數(shù)據(jù)管理平臺

 陜公網(wǎng)安備 61019002000171號
陜公網(wǎng)安備 61019002000171號



