美林數據技術專家團隊 | 工業大數據分析,怎么做?
2021-11-05 13:58:21
次
認識工業大數據
什么是工業大數據?
我們先看看維基百科的說法:“工業大數據(Industrialbig data)是構成工業人工智能的重要元素,指由工業設備高速產生的大量數據,對應不同時間下的設備狀態,是物聯網中的訊息。此一詞語在2012年隨著工業4.0的概念而出現,也和信息技術行銷流行的大數據有關,工業大數據也意味著工業設備產生的大量數據有其潛在的商業價值。工業大數據會配合工業互聯網的技術,利用原始資料來支援管理上的決策。”
百度百科是這樣說的:“工業大數據是指在工業領域中,圍繞典型智能制造模式,從客戶需求到銷售、訂單、計劃、研發、設計、工藝、制造、采購、供應、庫存、發貨和交付、售后服務、運維、報廢或回收再制造等整個產品全生命周期各個環節所產生的各類數據及相關技術和應用的總稱。其以產品數據為核心,極大延展了傳統工業數據范圍,同時還包括工業大數據相關技術和應用。其主要來源可分為以下三類:第一類是生產經營相關業務數據。第二類是設備物聯數據。第三類是外部數據。”
不同的說法體現了對工業大數據不同的認知角度。但毋庸置疑的是,工業大數據為創新制造業企業的研發、生產、運營、維保、營銷等提供了全方位支撐!

工業大數據如此重要,我們當然要立刻開展基于工業大數據的分析、挖掘工作,以便從中獲取重要的價值。且慢,工業數據具有不同于關系型業務數據的特殊性,使其難以直接使用現有數據分析工具。
工業大數據的特點
經典數據分析方法通常面向關系表數據結構(DataFrame)。無論是業務信息化系統中具有復雜數據關聯的表結構,還是面向分析專用的冗余數據寬表都會用到這一數據結構。它們同樣具有下面這些特征:
2、各行數據在同一列具有相同的數據類型,各列之間可以不同。
3、各列數據類型通常為基本類型,即數值型、文本型、布爾型等。
4、各行數據之間具有獨立性,沒有依賴關系。
關系表數據結構既是關系型數據庫所使用的基本邏輯模型,也是包括Excel、SPSS、R、Python—pandas、Spark等諸多數據分析處理軟件與框架所使用的數據模型,有大量數據分析方法針對這一數據結構。而工業制造領域常見的數據類型是信號數據,這種數據并不很適合使用關系表數據結構去進行表達。
信號數據是工業大數據的重要構成部分,其一般直接或間接來源工業設備本身,是反應工業設備現狀的重要參考。在設備故障診斷和健康預測(即PHM)應用中具有重要的價值。
和關系表數據相比,它存在以下特點:
1、每條信號數據內所有數據值均為同一類型數字,通常為浮點數值。
2、信號數據中數值的次序非常重要,其中包含關鍵信息。
3、一條信號數據內可以包含數百萬乃至更多標量值,通常難以用關系型數據庫逐一存儲。
4、針對工業信號數據存在著大量經典算法,以數字信號處理算法為主,這些算法與經典數據分析算法有很大差異。
5、大量機器學習、深度學習方法難以直接應用于原生信號數據形式。
可見,由于上述原因,面向關系表數據的處理、分析工具難以直接應用工業信號數據類型。換言之,當前工業信號分析領域的困境是:缺少面向工業信號數據的“數據分析+機器學習” 應用平臺。
面向工業大數據的分析工具
為解決工業大數據分析困境,Tempo大數據分析平臺開發提供了面向工業信號數據的專用分析工具包,該工具包是TempoAI為工業賦能的專用擴展功能之一。
通過該工具包,我們能快速便捷的使用拖曳方式,完成對信號的各種經典變換處理。更重要的是,本工具打通了主流及前沿的數據分析方法和機器學習技術應和工業信號類數據之間的壁壘。
現在工業工程師、質量工程師和PHM系統運維的小伙伴們可以將大量優秀的數據分析方法直接應用于工業現場數據挖掘。
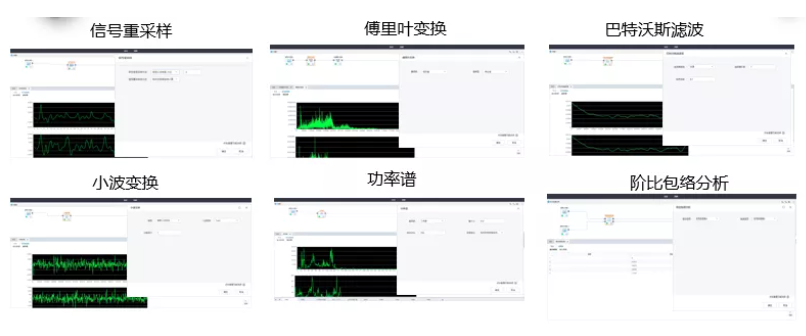
TempoAI 的信號處理工具包功能強大,下面我們看一下它具體都能做些什么吧。
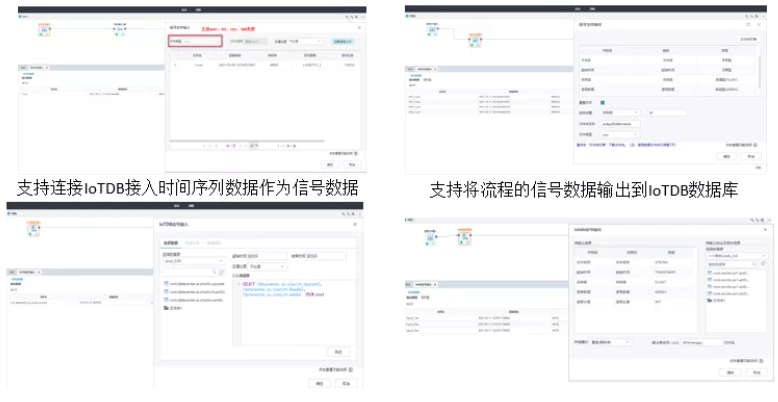
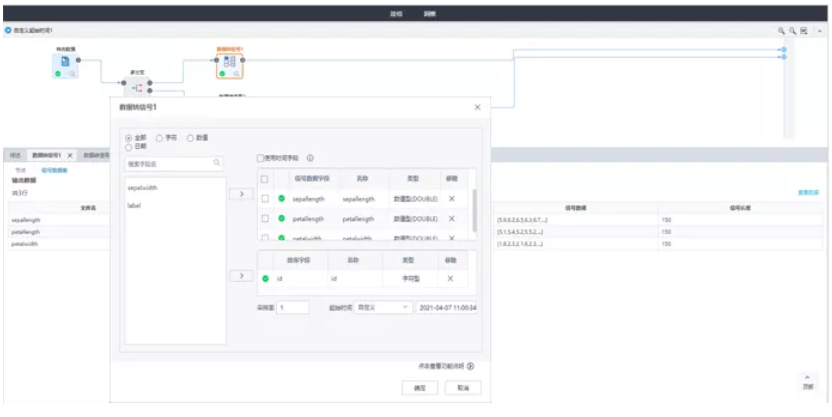
1、支持多種信號數據存儲形式的輸入與輸出
2、支持多種數字信號數據預處理操作
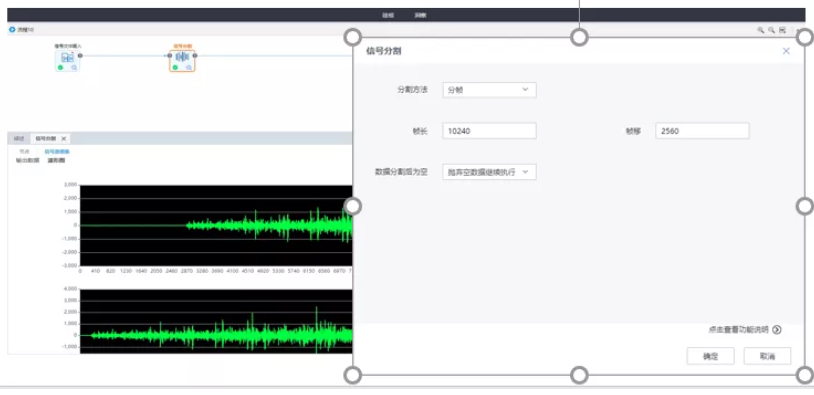
支持將信號數據按照不同的分割方法進行切分,支持按照分幀、分貝、時段、功率、平穩性、自適應分割方法。
3、支持多種數字信號處理方法拖曳式使用
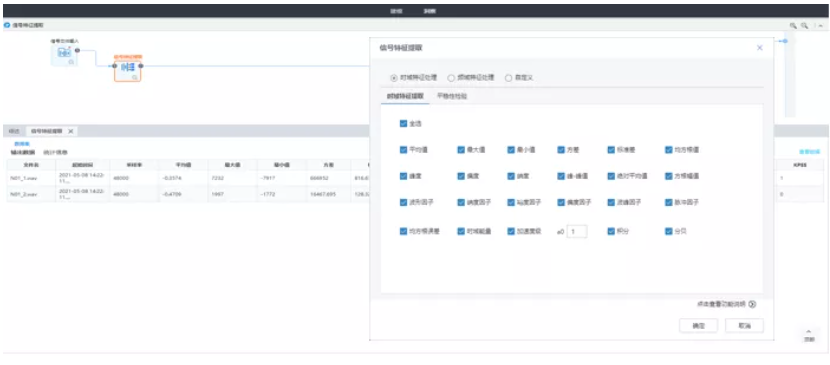
4、支持多種面向信號數據的特征工程方法
通過特征工程方法,可以將信號數據轉化為一系列特征量描述,從而便于用戶經典數據分析方法對其進行分析、建模等研究。
5、支持信號數據類型與關系表數據類型的相互轉換
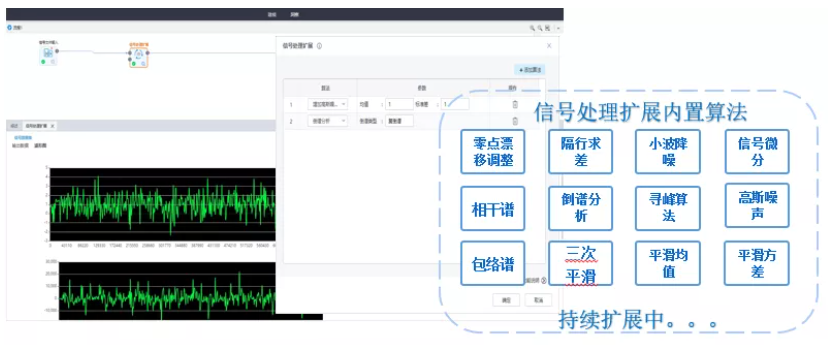
6、支持信號數據處理與特征提取功能自定義
信號處理擴展節點支持用戶通過選擇自定義的信號處理算法將信號數據進行處理,使信號數據處理更靈活更便捷。(自定義功能擴展需要管理授權)
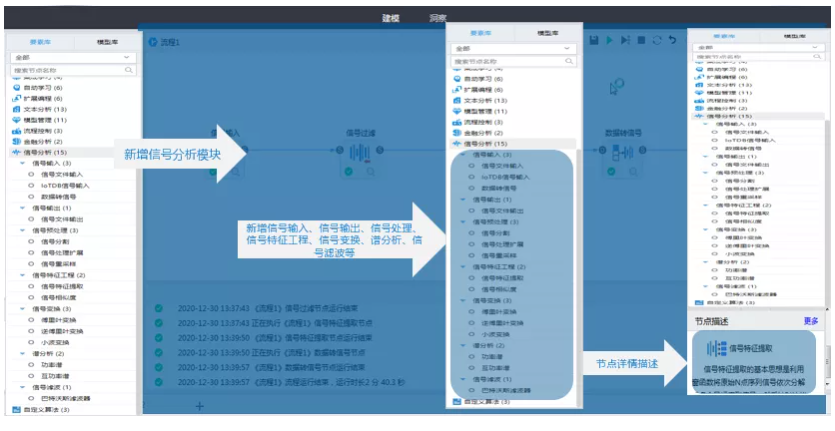
工業信號處理工具包在TempoAI里的位置是這樣的:
如下圖所示,平臺新增了信號分析模塊,將極大提高平臺對工業數據的兼容能力,尤其是工業信號數據,也為后續工業信號分析項目的大數據解決方案提供可能。
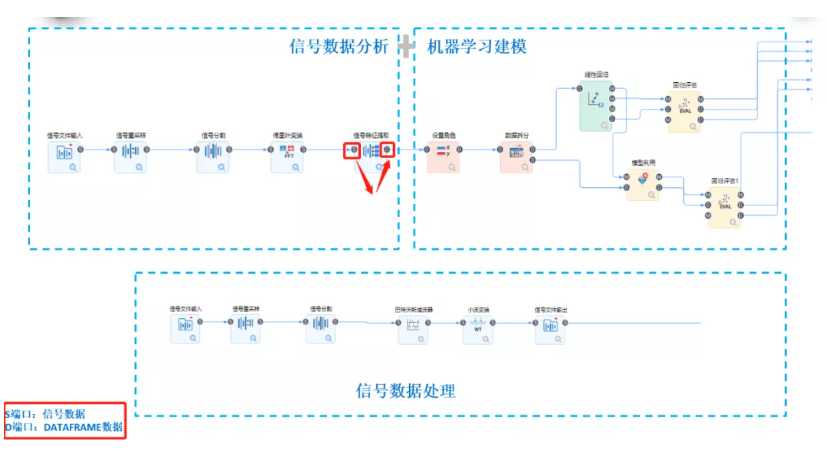
擴展后的技術路線主要包含三個層次:
1、最上層表示機器學習流程
其余CRISP-DM流程(跨行業數據挖掘標準流程)基本保持一致。
2、最下層就是經典數字信號處理流程
平臺內置了信號處理、信號變換、信號特征提取、譜分析以及信號濾波五大核心模塊,此外平臺集成了信號讀入和信號輸出兩個基本節點,這樣就可以實現經典信號分析流程端到端解決方法的暢通。
3、信號分析和機器學習融合
在平臺上體現為S端口(信號數據)和D端口(關系型數據)的連接。目前融合的核心組件是信號特征提取和S轉D。前者通過信號特征提取,完成機器學習或深度學習建模中特征工程的任務。后者完成信號數據機理分析結果的關系型轉存。
“信號分析+機器學習”其核心思路是基于信號分析算子完成信號數據的特征工程的功能。在實際使用信號分析工具包進行數據分析時,信號處理算法節點與數據分析節點的結合一般是下面這個樣子的。(紅框中是信號處理節點部分)
一個示例
現在我們用一個工業數據分析的例子來實際看一下信號處理工具包的使用。某風力發電機結構由三相感應發電機、冷卻箱和單級行星齒輪箱組成。齒輪的前后支撐都是深溝球類型的軸承,容易發生故障。現有以下需求:基于發電機組中發電機前軸承的振動信號實現軸承故障特征自適應提取和復合特征提取。
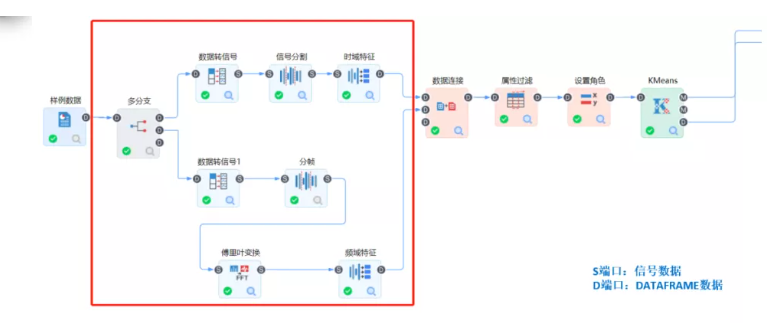
1、軸承故障特征自適應提取
分析說明:振動信號的時域信號存在在強弱不等的沖擊波形,但由于大量背景噪聲的干擾,使得這些沖擊的規律性和特征性不明顯。但其頻域信號中,高頻成分較為豐富。
實現路線:小波變換+信號特征提取
過程簡介:樣例數據和數據轉信號節點完成關系型數據向信號數據的轉變,然后基于離散小波變換,通過指定小波基函數和分解層數,對原信號數據實現多尺度的細分,最后基于這些細分信號數據,提取對應的信號特征。
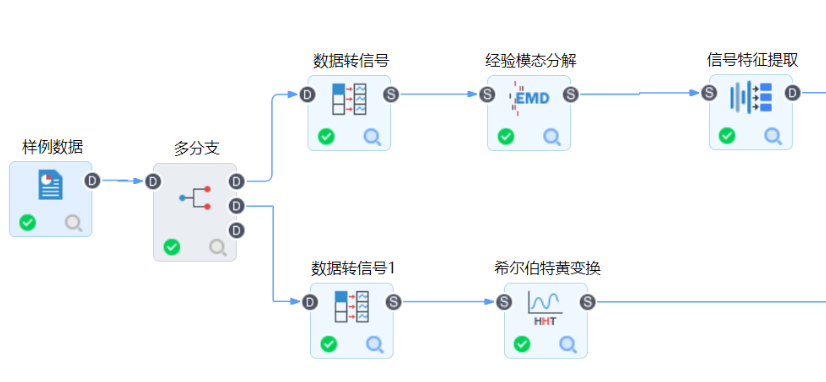
2、復合特征提取
分析說明:此時的振動信號頻譜圖很難看到明顯的故障信息。
實現路線:經驗模態分解+信號特征提取(或小波變換+信號特征提取)
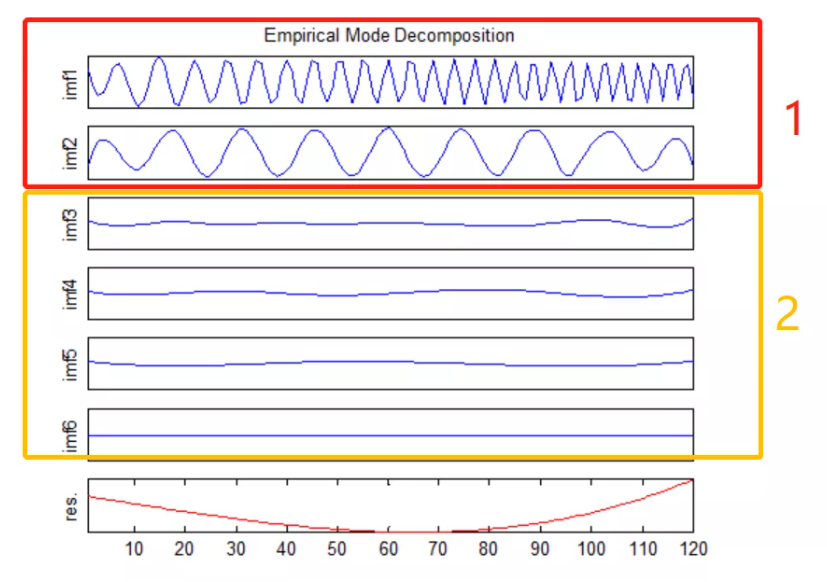
過程簡介:雖然與上述子問題的實現路線一致,但是側重點不同。這里信號特征提取只是輔助驗證,重點在于經驗模態分解(或小波變換)的分解和重構。以經驗模態分解為例:
當前信號被分成了6個模態函數和1個殘差余量。從波形圖上我們發現IMF1和MIF2的振動頻率比較相近,IMF3~IMF6比較相近。
所以據此,我們可以將相近的模態函數進行簡單相加(這里通過希爾伯特黃變換實現)形成新的信號,這些新信號的特征就是我們想要的符合特征。當分解層數較多時,各IMF分量比較接近時,我們可以選用信號特征提取中的特征幫助實現對其的分組(如以分貝、加速度級等)。
這樣,我們就獲得了這一類風機的典型運行工況特征。將這些特征提取出來后,就可以使用統計分析去發現風機運行的規律,或者將大量風機運行數據積累形成訓練數據,構建人工智能模型,以發現風機的運行異常等。
總而言之,TempoAI 的信號處理工具包解決了工業大數據分析中遇到的數據分析方法難以直接應用的問題,使得深入挖掘工業大數據,發現工業大數據價值變得便捷易行。感興趣的朋友們,請趕快嘗試吧!





























 Tempo商業智能平臺
Tempo商業智能平臺 Tempo人工智能平臺
Tempo人工智能平臺 Tempo數據工廠平臺
Tempo數據工廠平臺 Tempo指標平臺
Tempo指標平臺 Tempo數據治理平臺
Tempo數據治理平臺 Tempo主數據管理平臺
Tempo主數據管理平臺











 陜公網安備 61019002000171號
陜公網安備 61019002000171號



