AI時代,數(shù)據(jù)挖掘過時了嗎?—企業(yè)數(shù)據(jù)挖掘成功之道(理論篇)
2019-06-06 15:21:05
次
大數(shù)據(jù)時代、人工智能時代,機器學習、人工智能、深度學習、集成學習……概念漫天飛,數(shù)據(jù)挖掘似乎成為一個過時技術和概念。今天小編結(jié)合多年專業(yè)學習與研究經(jīng)驗,從實踐應用的角度重新梳理一下“數(shù)據(jù)挖掘”,讓您能夠拋開概念了解本質(zhì)!
數(shù)據(jù)挖掘(Data Mining)隸屬于知識發(fā)現(xiàn)(KDD)的范疇,是(劃重點)基于人工智能、機器學習、模式識別、統(tǒng)計學和數(shù)據(jù)庫等交叉方法,在數(shù)據(jù)中特別是大數(shù)據(jù)及海量數(shù)據(jù)中發(fā)現(xiàn)規(guī)律的過程,是從一個數(shù)據(jù)中提取、融合、處理信息,并將其轉(zhuǎn)換成可理解的結(jié)構(gòu)數(shù)據(jù)、可視化的分析圖表、可解釋的規(guī)律結(jié)論,以進一步響應業(yè)務分析的需求。它不是一個簡單的概念或者技術,而是一種解決問題的思路和方法,是一個知識綜合應用的技術集合。
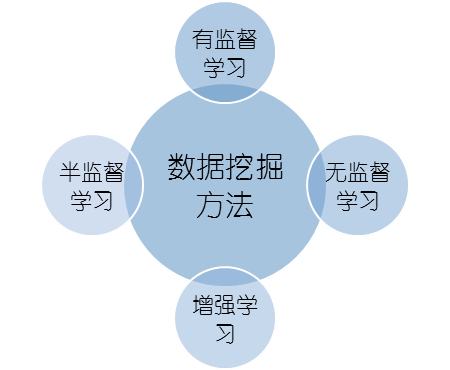
數(shù)據(jù)挖掘涉及知識面廣,技術點多。在面對復雜多樣的業(yè)務分析場景時,如何做出有效的數(shù)據(jù)挖掘分析方案其實是有一套可遵循的方法體系。針對不同的分析數(shù)據(jù)和業(yè)務場景,數(shù)據(jù)挖掘的方法可以分為監(jiān)督學習、無監(jiān)督學習、半監(jiān)督學習、增強學習,每種方法都有其適應的分析場景和數(shù)據(jù)基礎。
監(jiān)督式學習是基于標簽化的訓練資料學習或建立一個映射模式, 依此模式推測新的實例;它包括:分類、回歸、估計等。 注意,定義強調(diào)‘標簽化的訓練資料’,這就要求分析的樣本數(shù)據(jù)是有標注的。
半監(jiān)督學習是指訓練集同時包含有標記樣本數(shù)據(jù)和未標記樣本數(shù)據(jù),并且不需要人工干預,讓學習器不依賴外界交互、自動利用少量的標注樣本和大量的未標注樣本進行訓練和分類。半監(jiān)督學習對于減少標注代價,提高學習器性能具有非常重大的實際意義。
無監(jiān)督學習是指沒有給定事先標記過的訓練示例,自動對輸入的數(shù)據(jù)進行分類或分群,包括:聚類、關聯(lián)規(guī)則分析、部分統(tǒng)計分析等。
增強學習(Reinforcement learning)即強化學習,強調(diào)基于環(huán)境而行動,以取得最大化的預期利益。它采用的是邊獲得樣例邊學習的方式,在獲得樣例之后更新自己的模型,利用當前模型來指導下一步行動,例如博弈論、控制論、仿真優(yōu)化、群體智能。
明確了業(yè)務分析場景和數(shù)據(jù)挖掘的方法,接下來就要思考如何完成數(shù)據(jù)挖掘分析的目標。一般情況下,基于一定的業(yè)務場景和挖掘分析目標,數(shù)據(jù)挖掘的基本流程可以總結(jié)為以下幾個階段:數(shù)據(jù)探索、數(shù)據(jù)預處理、數(shù)據(jù)建模、模型評估和模型部署應用。
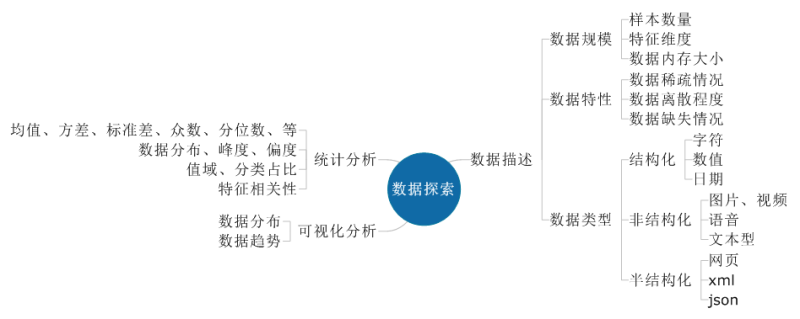
數(shù)據(jù)探索
數(shù)據(jù)探索是對建模分析數(shù)據(jù)進行先導性的洞察分析,利用繪制圖表、計算某些特征量等手段,對樣本數(shù)據(jù)集的結(jié)構(gòu)特征和分布特性進行分析的過程。 該步驟有助于選擇合適的數(shù)據(jù)預處理和數(shù)據(jù)分析技術,它是數(shù)據(jù)建模的依據(jù),比如:數(shù)據(jù)探索發(fā)現(xiàn)數(shù)據(jù)稀疏,建模時則選擇對稀疏數(shù)據(jù)支持相對較好的分析方案;如果數(shù)據(jù)包含文本數(shù)據(jù),建模時則需要考慮基于自然語言處理相關技術等。
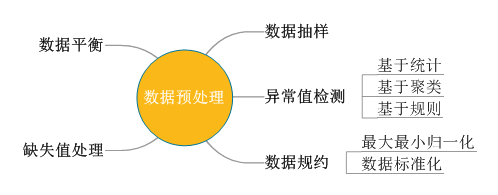
數(shù)據(jù)預處理
數(shù)據(jù)預處理是將不規(guī)整的業(yè)務數(shù)據(jù)整理為相對規(guī)整的建模數(shù)據(jù)(比如,數(shù)據(jù)缺失處理、異常值檢測處理等操作)。數(shù)據(jù)的質(zhì)量決定了模型輸出的結(jié)果,即數(shù)據(jù)決定了模型的上限,所以我們需要花大量的時間來對數(shù)據(jù)進行處理。在數(shù)據(jù)預處理階段,如果數(shù)據(jù)存在缺失值情況而導致建模過程混亂甚至無法進行建模,則需要做缺失值處理,缺失值處理分為刪除存在缺失值的記錄、對可能值進行插補及不處理3種情況;如果建模數(shù)據(jù)存在數(shù)據(jù)不均衡情況,則需要考慮數(shù)據(jù)平衡處理,解決這一問題的基本思路是讓正負樣本在訓練過程中擁有相同的話語權(quán),比如利用采樣和加權(quán)等方法;如果分析數(shù)據(jù)量較大,而建模分析又不強制全部數(shù)據(jù)參與建模分析(比如統(tǒng)計分析隨機選取部分數(shù)據(jù)作為分析對象),或者建模過程需要全量樣本的部分數(shù)據(jù),則需要做數(shù)據(jù)抽樣,包括隨機抽樣、等距抽樣、分層抽樣等方法;如果建模分析數(shù)據(jù)存在量綱、數(shù)量級上的差別,則需要做數(shù)據(jù)規(guī)約處理消除量綱數(shù)量級的影響;如果異常數(shù)據(jù)會對分析結(jié)果影響巨大,則需要做異常值檢測處理排除影響。
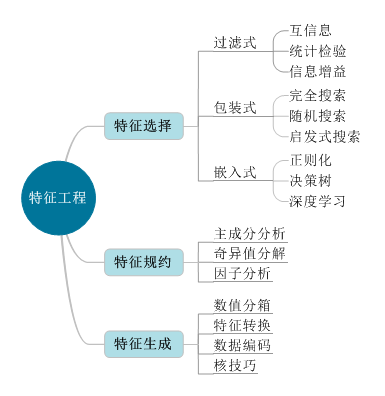
特征工程
理論上,數(shù)據(jù)和特征決定了模型的上限,而算法只是逼近這個上限而已,這里的數(shù)據(jù)指的是經(jīng)過特征工程得到的數(shù)據(jù),因此特征工程是我們進行機器學習必須重視的過程。特征工程的目的是最大限度地從原始數(shù)據(jù)中提取特征以供算法和模型使用。一般認為特征工程包括特征選擇、特征規(guī)約、特征生成三個部分。其中,特征選擇在降低模型復雜度、提高模型訓練效率、增強模型的準確度方面影響較大;在建模字段繁多的情形下,通過特征規(guī)約降低建模數(shù)據(jù)維度,降低特征共線特性對模型準確度的不利影響,從而提升模型的訓練效率;特征生成是在特征維度信息相對單一情況下為了提升模型準確性能而采取的維度信息擴充的方法體系。
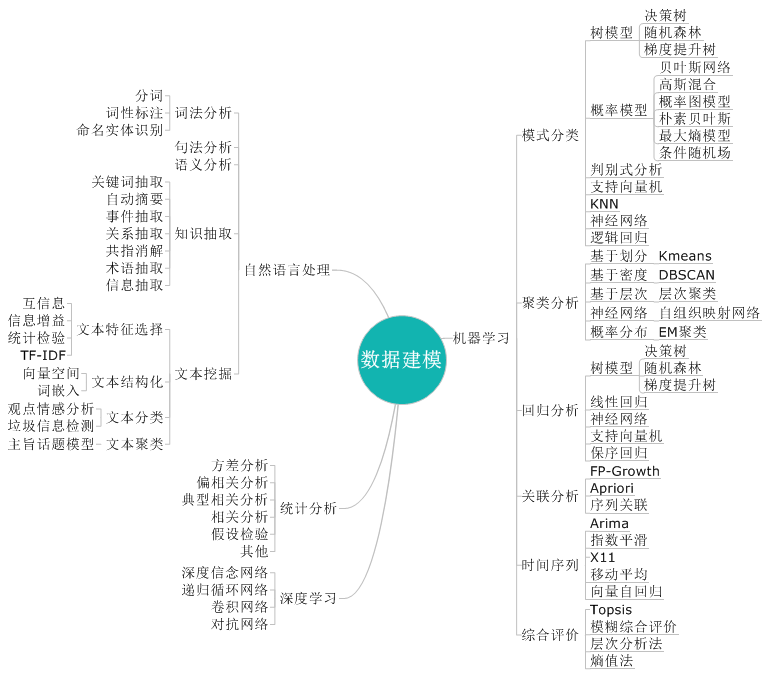
數(shù)據(jù)挖掘的核心階段是基于既定的數(shù)據(jù)和分析目標選擇適宜的算法模型進行建模訓練和迭代優(yōu)化。數(shù)據(jù)建模涉及的技術包括:機器學習、統(tǒng)計分析、深度學習,相關技術之間沒有一個明顯的區(qū)分界限,且功能互補。如果建模業(yè)務數(shù)據(jù)涉及到文本非結(jié)構(gòu)化數(shù)據(jù),則需要借助自然語言處理實現(xiàn)業(yè)務分析場景;面對一些調(diào)查數(shù)據(jù)分析統(tǒng)計意義給出決策結(jié)論時,則需要基于統(tǒng)計分析的相關技術;在機器學習領域,分類技術主要解決影響因素X和決策變量Y的問題,基于此目的我們所要做的就是尋找X和Y之間的函數(shù)關系。其中分類場景的實際應用Y是名詞型屬性,如用于故障預測、精準營銷等;回歸場景和分類場景類似,只是回歸場景中的決策變量Y是連續(xù)性的數(shù)值型數(shù)據(jù),如用于設備壽命預測、收視率預測等;聚類分析是在沒有決策變量Y的情況下,基于一定的規(guī)則(比如基于距離相近、基于曲線相似等)將樣本數(shù)據(jù)進行分群進而找出共性群體,如客戶細分,市場細分等;時間序列數(shù)據(jù)是基于歷史數(shù)據(jù)挖掘內(nèi)在的趨勢規(guī)律,進而實現(xiàn)對未來數(shù)據(jù)的預測分析,如銷量預測、產(chǎn)量預測等;關聯(lián)分析適用于挖掘多個事務項之間共現(xiàn)關聯(lián)關系,從而描述事物項中某些屬性同時出現(xiàn)的規(guī)律和模式,如產(chǎn)品關聯(lián)推薦、交叉故障等,關聯(lián)分析的一個典型例子是購物籃分析;綜合評價適用于在多因素、多層次復雜決策情況下對多個備選方案打分以輔助決策,如店鋪選址、客戶信用評分等;
深度學習領域涉及多種模型框架和操作使用技巧,其本身可以作為機器學習的特例, 同樣適用于機器學習多個應用場景。深度學習作為一種實現(xiàn)機器學習的技術,往往在數(shù)據(jù)量大、業(yè)務數(shù)據(jù)指標難以人工提取的情形下發(fā)揮著舉足輕重的作用, 它在圖像處理、語音識別、自然語言處理等領域具有其它機器學習算法無法企及的準確性能。
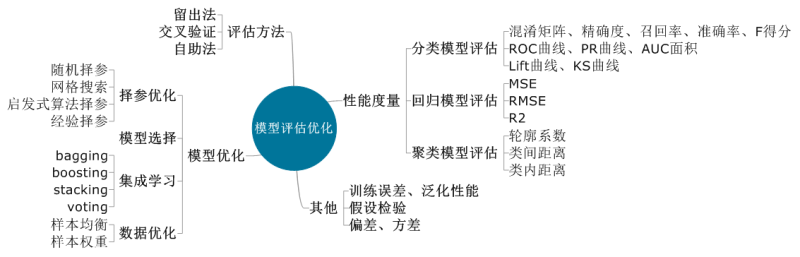
模型評估是評估所構(gòu)建的模型是否符合既定的業(yè)務目標,它有助于發(fā)現(xiàn)表達數(shù)據(jù)的最佳模型和所選模式將來工作的性能如何。模型評估秉承的準則是在滿足業(yè)務分析目標的前提下優(yōu)先選擇簡單化的模型。每個分析場景可以基于多種算法構(gòu)建多個模型,也可以依據(jù)模型優(yōu)化的方法體系做模型訓練優(yōu)化,而如何在訓練得到的多個模型中選擇最優(yōu)模型,可以選擇性能度量作為指標體系,進而基于一定的評估方法進行擇優(yōu)選擇。
模型部署及應用
模型部署及應用是將數(shù)據(jù)挖掘結(jié)果作用于業(yè)務過程,即將訓練得到的最優(yōu)模型部署到實際應用中;模型部署后,可使用調(diào)度腳本控制數(shù)據(jù)挖掘模型實現(xiàn)流程化運行。在模型日常運行過程中,可根據(jù)實際需求檢查模型運行結(jié)果是否滿足前端業(yè)務的實際應用,跟蹤模型運行情況,定期進行模型結(jié)果分析,并適時進行模型優(yōu)化。
以上內(nèi)容對數(shù)據(jù)挖掘涉及的知識體系做了簡要介紹,上述的知識體系涵蓋了實際挖掘分析所用方法體系的絕大部分內(nèi)容,希望讀者能夠通過本文對數(shù)據(jù)挖掘有個全局認識。在面對復雜的業(yè)務分析場景時,能夠有一個清晰嚴謹?shù)耐诰蚍治鏊悸罚M步明確可以對樣本數(shù)據(jù)做哪些分析以及如何科學地做挖掘分析。另一方面來說,在實際挖掘分析過程中,一個特定的挖掘分析場景只是涉及上述知識體系的一部分,每個分析場景涉及的知識點也不盡相同,全面掌握和深入理解挖掘知識體系是一個逐漸學習與積累的過程;這就需要我們在每一個挖掘場景下對涉及的知識點進行深入理解和知識擴充,并且對多個實踐過程進行循環(huán)往復的知識總結(jié)和經(jīng)驗積累。

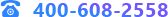






























字化轉(zhuǎn)型的四大典型場景,TempoBI來支持")
據(jù)分析上手難?2招幫你快速生成高質(zhì)量數(shù)據(jù)可視化報表")



 Tempo商業(yè)智能平臺
Tempo商業(yè)智能平臺 Tempo人工智能平臺
Tempo人工智能平臺 Tempo數(shù)據(jù)工廠平臺
Tempo數(shù)據(jù)工廠平臺 Tempo指標平臺
Tempo指標平臺 Tempo數(shù)據(jù)治理平臺
Tempo數(shù)據(jù)治理平臺 Tempo主數(shù)據(jù)管理平臺
Tempo主數(shù)據(jù)管理平臺



 陜公網(wǎng)安備 61019002000171號
陜公網(wǎng)安備 61019002000171號



