Tempo大數據分析平臺之深度學習解析
2020-05-18 16:03:12
次
2006年,Hinton在頂級期刊《科學》提出深度學習的概念,深度學習的概念源于人工神經網絡的研究,是一種多層深度學習結構,深度學習通過組合低層特征形成更加抽象的高層表示類別屬性或特征,發現數據的分布特征。
隨著研究的深入,深度學習在圖像處理、語音識別、自然語言處理等領域取得突破性進展,落實的具體行業上,多采取多個領域的多模融合實現具體應用,比如,機器人助手,首先,需要圖像處理模塊和語音識別模塊把語音信息和圖像信息轉化為文字描述,實現助手洞察外部的視覺和語音,其次,需要專門的深度學習網絡實現基于語言的語義理解,給出外部反饋信息。
隨著科技研究的深入,深度學習技術在最近幾年得到快速的發展,引起行業學者的極度關注。然而,深度學習對新入該領域的人來說門檻很高,基于此Tempo3.0為降低深度學習使用困惑集成了深度學習,平臺深度學習建模提供兩種方式:
- 面向無編程基礎的業務人員,可以基于平臺的深度學習模型集成節點(DNN、RNN)等進行深度學習建模;
- 面向具備編程基礎業務人員(具備Python編程基礎),可以基于平臺的深TensorFlow腳本節點進行深度學習建模;
TensorFlow腳本節點
1.1.TensorFlow簡介
隨著深度學習在圖像處理、語音識別、自然語言處理等領域取得突破性進展,深度學習編程框架也如火如荼的急速發展,其中,2015年11月9日,Google發布人工智能系統TensorFlow并宣布開源,得到深度學習領域的推崇。
TensorFlow™ 是一個采用數據流圖的方式用于數值計算的通用計算框架,能夠快速實現遞歸神經網絡(RNN)和卷積神經網絡(CNN)等的深度學習工具, 能夠靈活的架構在多種平臺,很方便的實現在CPU\GPU間的無縫切換。其中,數據流圖是用結點和線的有向圖來描述數學計算,節點(Nodes)表示數學操作,線(edges)表示在節點間相互聯系的多維數據數組,即張量(tensor)。
TensorFlow作為深度學習的通用編程計算框架,具備豐富的深度學習建模工具API接口,能夠方便快速的實現DNN、CNN、RNN、LSTM、DBN等深度學習模型,此外,也可用于其他線性或非線性組合建模應用,進而實現圖像處理、語音識別、自然語言處理等相關領域場景化應用。
1.2.TensorFlow on Spark
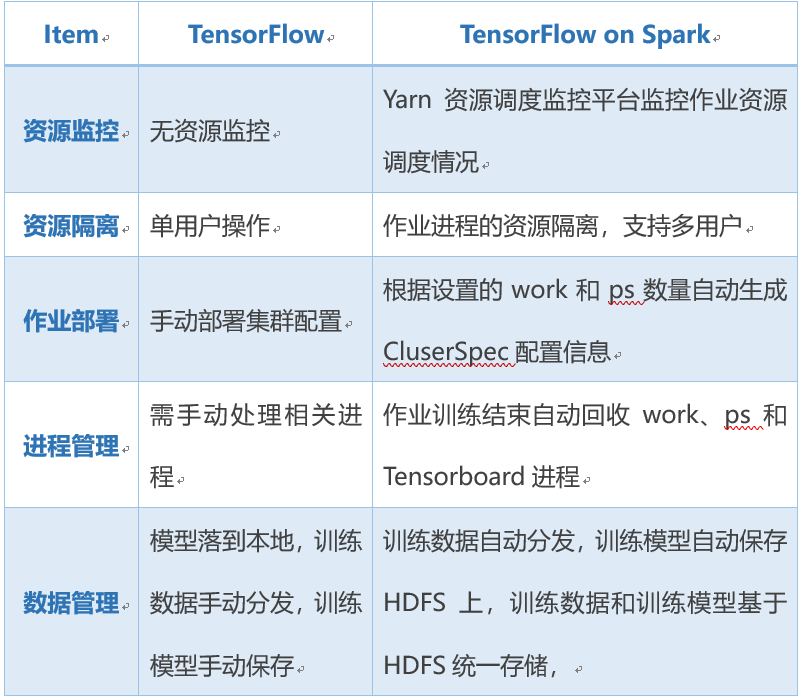
源生態TensorFlow存在諸多使用上不便的問題:資源利用和管理方面,資源利用不易管理,需手動配置資源,沒有集群資源管理和調度,集群資源負載不均,作業缺乏統一管理,不便對作業運行狀態跟蹤;數據管理方面,數據管理困難,訓練數據需手動分發,訓練模型需手動保存本地,此外,日志查看不方便;進程管理方面,進程遺留,需手動處理進程關閉。
TensorFlow on Spark解決了以上存在的問題,實現數據基于Spark RDD進行分布式分發,模型保存到HDFS分布式文件系統中,詳細功能如下表所示。
1.3.TensorFlow在Tempo3.0集成應用
Tempo大數據分析平臺將TensorFlow嵌入到挖掘流程中,實現TensorFlow節點和平臺其他節點無縫融合,同時規避了源生態TensorFlow存在諸多使用上不便的問題。
TensorFlow在Tempo3.0挖掘流程中執行過程如下:
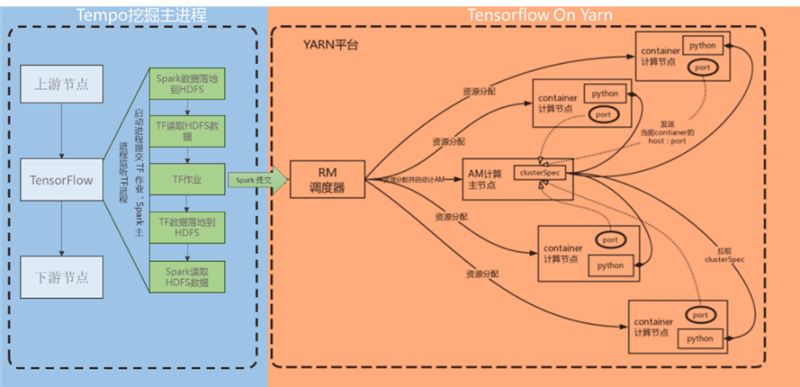
- 上游節點將數據處理完畢后,數據寫入HDFS分布式文件系統中,將文件路徑傳入TensorFlow節點,TensorFlow腳本節點啟動進程通過PySpark提交Spark作業,挖掘流程主進程駐留,并對TensorFlow腳本進程進行監聽;
- 由PySpark啟動TensorFlow集群和相關服務(TensorBoard等),讀取數據并分發到TensorFlow集群各節點進行作業處理,處理的數據輸出到HDFS分布式文件系統中,結束TensorFlow進程;
- 挖掘流程主進程監聽到TensorFlow進程結束后,從HDFS分布式文件系統中讀取TensorFlow輸出的數據,接著進入下面的作業流程。
1.4.TensorFlow腳本應用
(1)挖掘流程界面
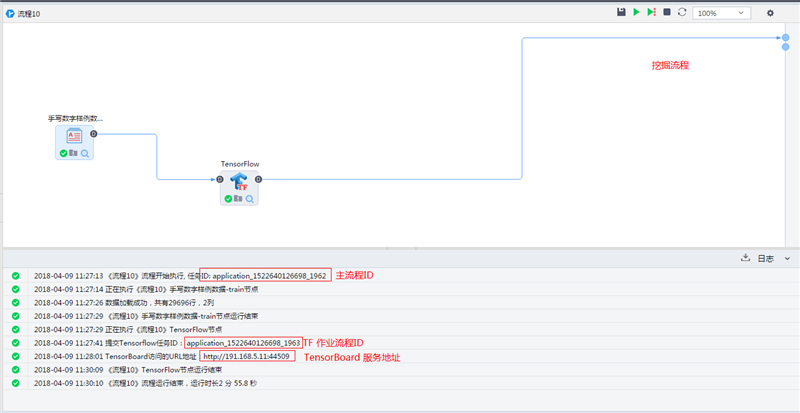
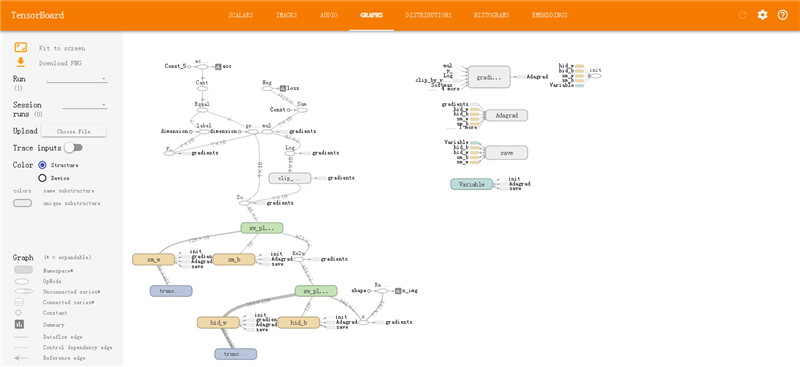
TensorFlow腳本在挖掘分析過程中可以和平臺其他挖掘分析節點無縫對接,其挖掘流程若下圖所示:
在流執行過程中,流程日志會輸出“TF Spark作業流程ID”和“TensorBoard服務地址”,根據“TF Spark作業流程ID”可以查看集群的資源調度情況以及跟蹤TF作業狀態,查看TF集群作業日志信息。
作業會基于HDFS模型路徑自動啟動TensorBoard服務,實現對TF作業過程進行時時建模洞察,雖則TF作業結束,TensorBoard服務也會終止以防服務駐留對集群資源的過度占用。
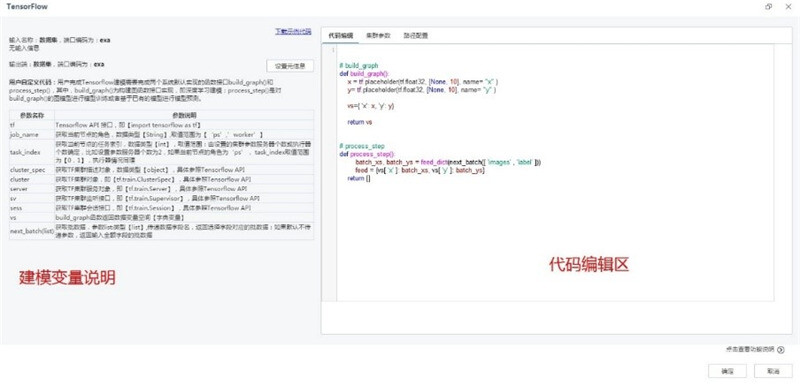
(2)腳本參數界面
TensorFlow腳本參數界面如下圖所示,界面分三個功能Tab頁:代碼編輯、集群參數、路徑配置。
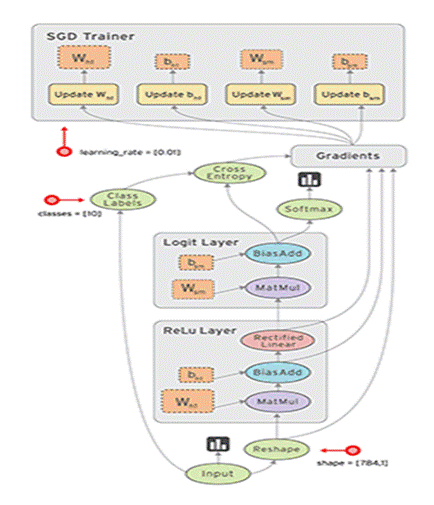
代碼編輯頁是用戶編碼建模界面,左面為可引用建模變量詳細說明,右邊為代碼編輯區。TensorFlow程序通常被組織成一個構建階段和一個執行階段. 在構建階段,執行步驟被描述成一個圖;在執行階段,使用會話執行圖中的操作。用戶基于Tempo完成深度學習建模需實現以下兩種函數接口build_graph和process_step,build_graph為構建圖函數接口,process_step為使用會話執行圖中的操作函數接口。
集群參數為深度學習建模過程中TensorFlow集群配置和模型訓練配置界面,可以配置集群參數服務器、執行器個數即執行器內存,模型訓練中的模型名稱、數據批大小、迭代次數等;路徑配置為TensorFlow集群部署環境配置界面。
模型集成節點
模型集成節點以參數界面配置的方式實現深度學習建模,模型集成節點幫助用戶快速高效的進行深度學習建模,而不要求用戶具備編碼基礎,僅需用戶具備一定的深度學習基本原理知識。平臺規劃集成DNN、RNN、LSTM、CNN等常用深度學習模型實現分類、回歸、時間序列等業務場景。
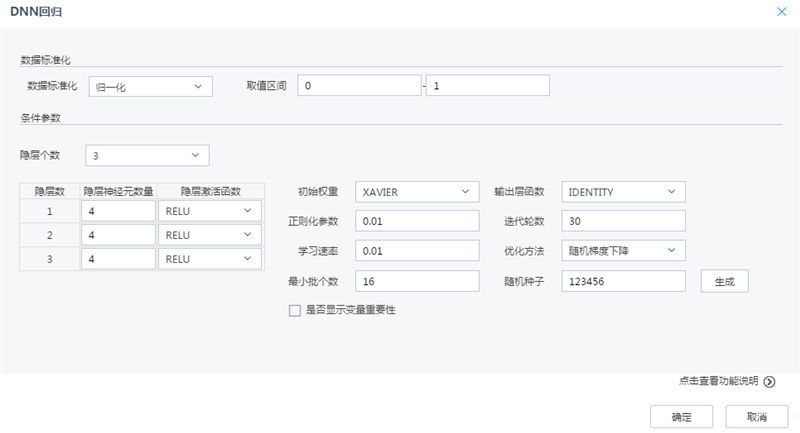
目前,平臺集成了DNN分類、DNN回歸、LSTM回歸的深度學習模型集成,其中,以DNN回歸為例介紹深度學習模型集成節點的使用,其他節點使用模式相似。下圖為DNN回歸建模參數界面:
數據預處理:基于數據標準化方法實現數據預處理,提高建模的效率和精度;
網絡機構:支持配置DNN網絡結構如:隱層個數、隱層神經元個數、激活函數、輸出層函數;
模型訓練:支持配置DNN模型網絡空間初始權重初始化方式、參數尋優方法、正則化參數、模型訓練次數、學習速率、最小批樣本個數;





























 Tempo商業智能平臺
Tempo商業智能平臺 Tempo人工智能平臺
Tempo人工智能平臺 Tempo數據工廠平臺
Tempo數據工廠平臺 Tempo指標平臺
Tempo指標平臺 Tempo數據治理平臺
Tempo數據治理平臺 Tempo主數據管理平臺
Tempo主數據管理平臺








 陜公網安備 61019002000171號
陜公網安備 61019002000171號



