醫保反欺詐:用大數據守住人民的保命錢
2021-01-25 15:35:37
次
2020年12月28日,國家醫保局公布了新版《國家基本醫療保險、工傷保險和生育保險藥品目錄(2020年)》。本次目錄調整首次嘗試對目錄內藥品進行降價談判。在醫保談判現場,談判專家和藥企代表你來我往,上演“靈魂砍價”!
“4.4元,4太多,難聽,再便宜點。”“降價別跟擠牙膏似的!”
最終,119種藥品談判成功,平均降價50.64%。通過調整醫保藥品結構、優化藥品價格,在不額外增加醫保基金負擔的情況下,滿足了更多百姓看病的用藥需求。新目錄將于2021年3月1日在全國范圍啟用。值得關注的是,最新版國家新冠肺炎診療方案所列藥品已全部納入國家醫保目錄,為打贏這場仍在蔓延的新冠疫情阻擊戰注入了必勝的信心。
社會醫療保險作為我國基礎保險制度,醫保基金被形象地稱為老百姓的“保命錢”。談判代表在談判桌上一分一厘的“較真”,就是為了老百姓守住這份“保命錢”。然而,有一部分人為了自己的利益,在報銷規則上鉆空子,利用偽造發票、重復就診、重復開藥、冒名就醫、支付非醫保藥費或診療項目等各種方式騙取醫保基金,導致醫保基金大量流失。
中國社會保障學會日前發布的《中國醫療保障發展報告2020》中,全球因欺詐導致的醫療保險基金損失占醫保基金支出的4.57%。以此為標準,按照2019年全國醫保總支出20854億元計算,2019年全國醫保基金因欺詐的損失高達953.03億元。
2020年7月9日,我國第一部國家層面的醫保基金監管文件《關于推進醫療保障基金監管制度體系改革的指導意見》由國務院辦公廳印發,《意見》中要求依托現代技術,強化事前、事中監管是一大亮點。
大數據、人工智能發展至今已在諸多領域成功應用落地,發揮了巨大的價值。在醫療領域,大數據、人工智能等技術為醫保反欺詐增加了新的防控手段。
通過機器學習算法模型對結算數據、電子病歷等平臺采集的住院、門診相關數據進行全方位、多維度、長周期的分析,挖掘其中的行為模式、常用藥物和治療項目,再根據聚類算法,將存在其中的真實性問題數據識別出來,建立醫保反欺詐模型,自動識別醫保欺詐行為,減少醫保基金的流失。
基于數據挖掘的標準流程分為五個大的步驟——業務理解、數據理解、數據準備、建立模型和模型評估。
醫保反欺詐分析
在本案例中,醫保反欺詐分析的流程包括:業務理解、數據收集和理解、數據預處理、特征分析、樣本集篩選、模型訓練與評估。
1、業務理解
首先是對醫保欺詐行為進行業務理解,分解出醫保欺詐的具體行為和相關特征。以醫保欺詐中的個人騙保和組織騙保為例,聚焦醫保資金套現的具體手段,包括但不限于虛報病情、偽造票據、掛名住院、冒名就醫等。
2、數據收集和理解
基于業務理解,確定需要收集的數據內容。通過醫保結算等系統收集患者信息表、消費明細表、處方信息表、住院記錄等,并對醫保反欺詐模型構建所需要的數據字段進行篩選。
3、數據預處理
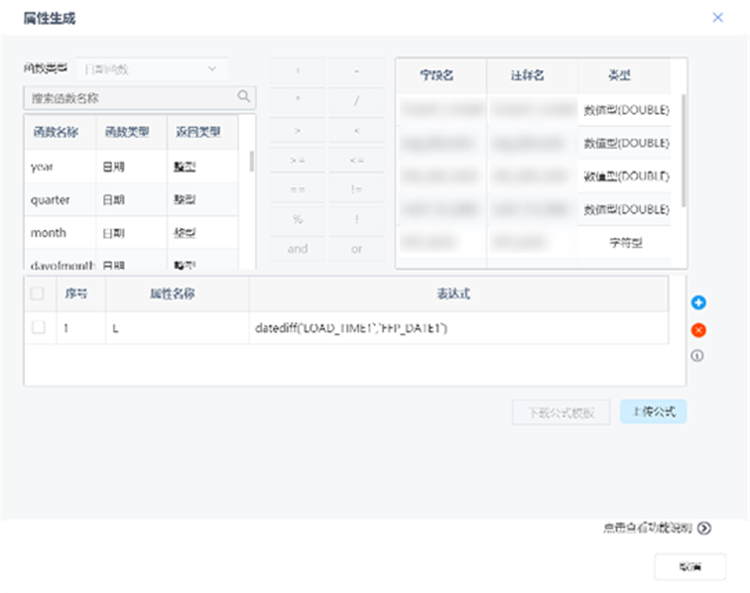
將醫保報銷系統中的原始數據導入TempoAI。為了確保模型質量,首先需要對數據信息進行預處理操作。通過平臺的“屬性過濾”節點抽取所需字段,并完成字段類型轉換,使用“重命名”、“數據過濾”、“數據連接”等節點完成數據的處理工作,得到包括報銷單號、醫保編號、門診號、住院號、門診掛號日期、住院日期、出院結算日期、報銷金額、病種編碼等分析所需的數據。
4、特征分析
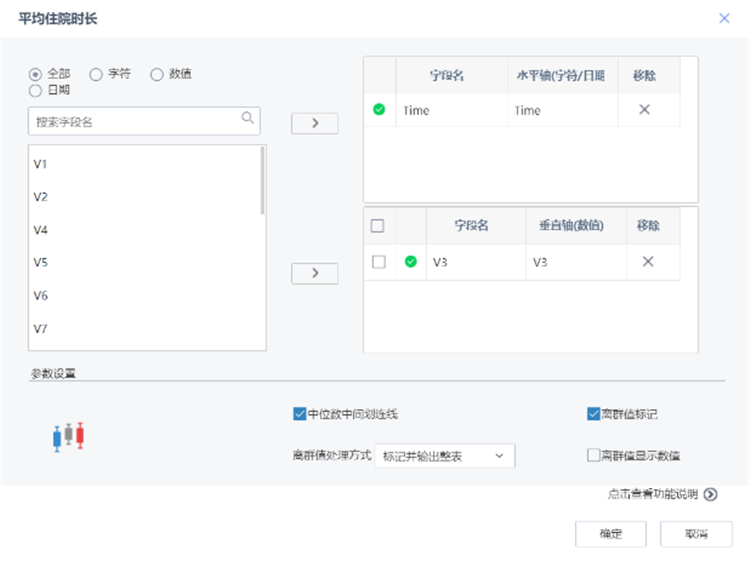
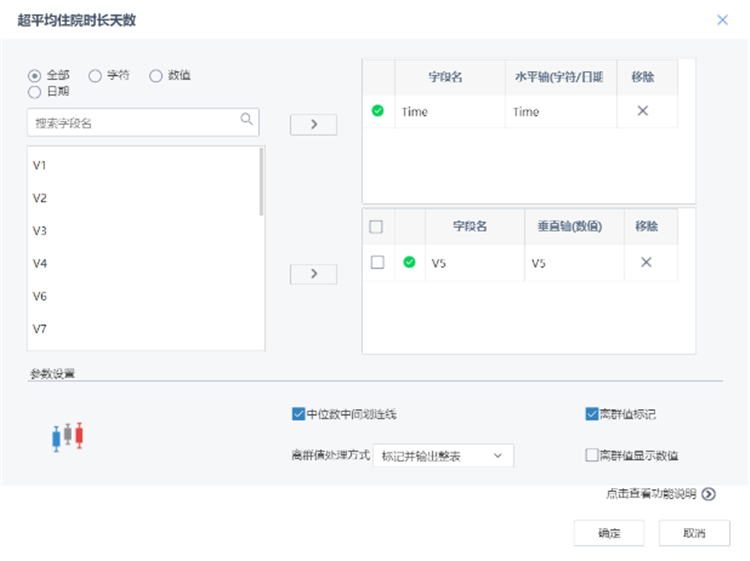
在完成數據預處理后,從這些數據中探索欺詐行為的特征,例如:醫保賬號在過去一段時間的平均門診次數、住院次數、住院時長、報銷金額、報銷次數等內容是否遠超平均水平,如果有就意味存在欺詐的嫌疑。針對這些特征,通過“數據過濾”與“屬性生成”節點,篩選、計算、新增所需的字段,包括平均門診次數、平均住院次數、平均住院時長、平均報銷金額、超平均住院時長、超平均報銷金額次數共計六個數據。
5、樣本集篩選
通過箱線圖對數據的分布情況進行觀察,以確保所獲取的“特征字段”數據的可靠性。
通過箱線圖確認特征的可靠性后,基于這些特征對樣本數據進行聚類分析,獲取到正、負樣本的兩個數據集。正樣本為“欺詐行為”,負樣本為“正常行為”。按比例用隨機抽樣抽取正負樣本,形成訓練集與測試集,為接下來的模型訓練與評估提供數據支撐。
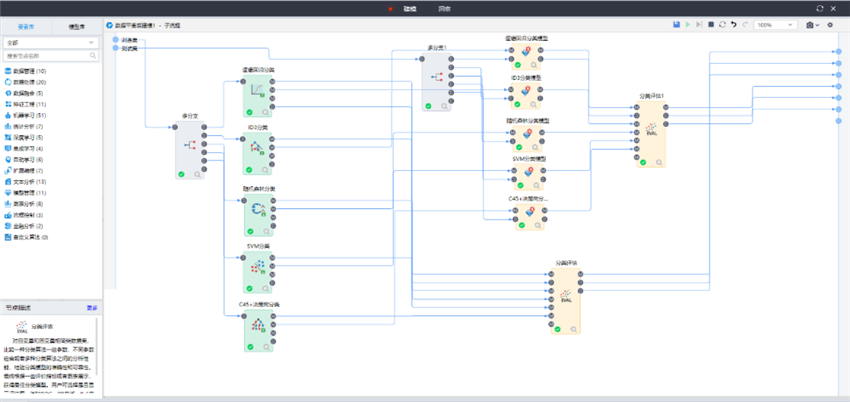
6、模型訓練與評估
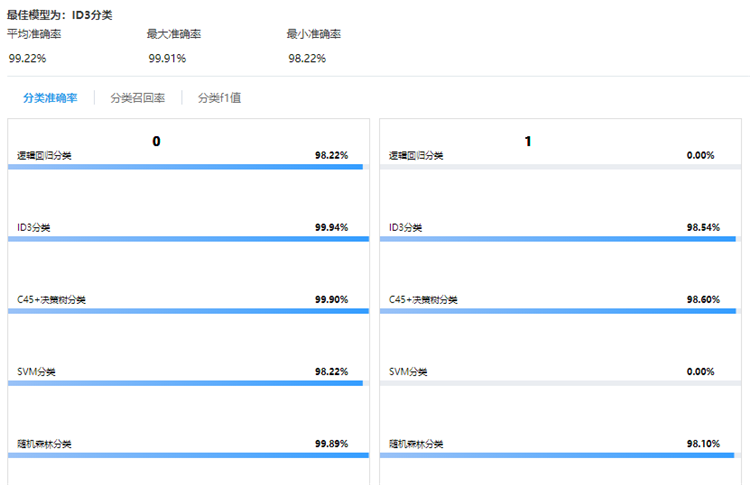
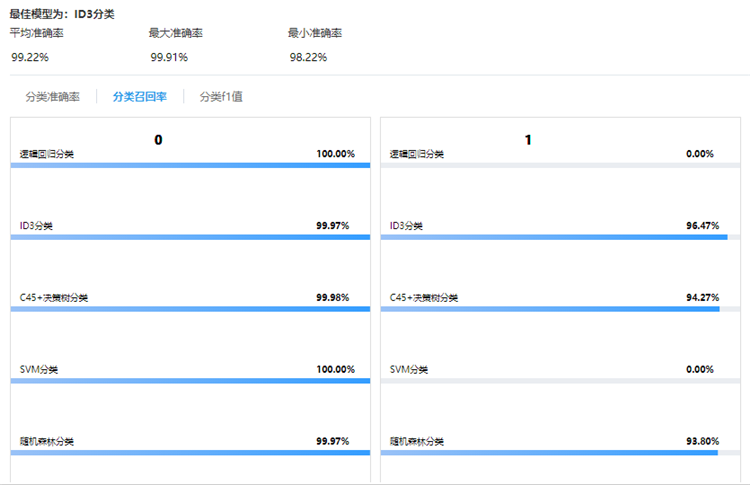
選擇邏輯回歸分類、隨機森林分類、SVM分類、ID3分類、C45+決策樹分類五種分類算法進行模型訓練,通過驗證數據集對訓練好的模型進行評估。
模型運行后,在洞察頁面重點關注模型評價“召回率”與“精度”,召回率高意味著通過模型,用戶可以識別更多的可疑單號,而精度高則意味識別的可疑單號是欺詐行為的可能性更高。可以看到,在“召回率”與“精度”兩個評價中,最佳模型選項均為ID3分類。
以上就是利用TempoAI建立醫保反欺詐模型的整個流程。
醫保反欺詐模型價值
醫院可以通過識別醫保欺詐行為的支付訂單,發現風險后延遲支付,并通知人工進行二次核驗,降低因為核算報銷時發現不合理報銷單拒付的風險,為醫院年底醫保報銷結算的金額數量提供保障。
醫保中心或地方財政部門可以在月度或年度醫保核算時候通過模型識別風險訂單,自動合計風險訂單涉及金額并輸出風險訂單,為工作人員工作提供便捷的同時,為地方財政的醫保資金盤子減壓。
商業用戶,例如各類保險公司與金融機構可以利用醫保反欺詐行為識別模型來識別風險訂單,為企業降低資金風險與人力成本。
結語
醫保基金是整個社會民生基礎之一,是每一個參保人的救命錢。守住醫保基金的安全,就是守住社會底線。在當前新冠疫情仍在蔓延的特殊時期,為醫保基金保駕護航有著尤為重要的意義。
正常需要幾周的建模工作量,通過TempoAI在幾小時內就可以快速構建出“醫保反欺詐行為模型”,利用大數據、機器學習自動識別出欺詐行為,為工作人員提供判斷依據,減少因欺詐產生的基金流失。
當然,隨著醫保欺詐行為越來越隱匿、手段越來越多樣,反欺詐模型構建的復雜程度也越來越高。不過,隨著大數據、人工智能等技術手段不斷深入應用,相信百姓的救命錢袋也會越來越安全,社會醫療保險的根基也會越來越穩固。
社會醫療保險作為我國解決民生防治疾病問題推出的基礎保險制度,醫保基金被形象地稱為老百姓的“保命錢”。談判代表在談判桌上一分一厘的“較真”,就是為了老百姓守住這份“保命前”。然而,有一部分人為了自己的利益,在報銷規則上鉆空子,利用偽造發票、重復就診、重復開藥、冒名就醫、支付非醫保藥費或診療項目等各種方式騙取醫保基金,導致醫保基金大量流失。





























 Tempo商業智能平臺
Tempo商業智能平臺 Tempo人工智能平臺
Tempo人工智能平臺 Tempo數據工廠平臺
Tempo數據工廠平臺 Tempo指標平臺
Tempo指標平臺 Tempo數據治理平臺
Tempo數據治理平臺 Tempo主數據管理平臺
Tempo主數據管理平臺





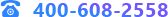





 陜公網安備 61019002000171號
陜公網安備 61019002000171號



