大話數據挖掘——預測分析之決策樹方法
2021-03-02 18:18:58
次
接上一篇《大話數據挖掘之預測分析》
徐教授的PPT又翻開了新的一頁,他將光筆指向屏幕上的樹狀圖,講道:“所謂決策樹就是一個類似流程圖的樹型結構,樹的最高層結點就是根結點,樹的每個內部結點代表對一個屬性(取值)的測試,其分支就代表測試的每個結果,而樹的每個葉結點就代表一個類別。從根節點到葉子節點的每一條路徑構成一條‘IF…THEN…’分類規則。”
李部長凝視著大屏幕上的決策樹,明白了其中的奧妙,不禁道:“決策樹方法實際上就是通過一定的評判策略判定哪一個屬性對分類最為重要,就將其作為根節點,然后再判斷余下的節點中最重要的的節點,直到葉子節點。”
“好,理解得還比較透徹。不過,李部長,什么樣的節點才可以標注為葉子節點呢?”徐教授問。
李部長吱吱唔唔:“好像有三種情況……”
“對,附合以下三個條件之一的節點就可為葉子節點:(1)節點的樣本集合中所有的樣本都屬于同一類;(2)節點的樣本集合中所有的屬性都已經處理完畢,沒有剩余屬性可以用來進一步劃分樣本,這時候采用子集中多數樣本所屬于的類來標記該節點;(3)節點的樣本集合中所有樣本的剩余屬性取值完全相同,但所屬類別卻不同,此時用樣本中多數類來標示該節點。”
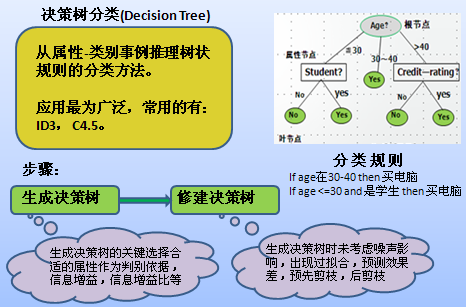
徐教授接著說:“決策樹算法的典型代表是ID3(Interactive Dicremiser version 3)算法,它是由Quinlan等人于1986年提出的,是當前機器學習領域中最有影響力的算法之一。其核心思想是在決策樹的構建過程中采取基于信息增益的特征選擇策略,即選取具有最高信息增益的屬性作為當前節點的分裂屬性,使得對結果劃分中的樣本分類所需要的信息量最小。以此構造與訓練數據一致的一棵決策樹,從而保證了決策樹具有最小的分支數量和最小的冗余度。”
李部長:“ID3算法思想簡單,并且由其構造的決策樹對樣本的識別率比較高。在實際應用中,ID3算法還有什么不足之處嗎?”
徐教授按了一下光筆,并說:“請看大屏幕ID3算法的缺點主要表現在以下幾個方面。”
ID3算法的不足之處
(1)ID3算法在搜索過程中不能再回溯重新考慮選擇過的屬性,從而收斂到局部最優解而不是全局最優解;
(2)信息增益的度量偏袒于屬性取值數目較多的屬性,這不太合理;
(3)ID3算法只能處理離散值得屬性,不能處理連續屬性;
(4)當訓練樣本過小或者包含有噪聲的時候,容易產生過度擬和(Overfitting)現象。
馬處長看著屏幕,問道:“徐老師,那怎樣改進ID3算法呢?”
徐教授回答道:“針對ID3算法的不足,Quinlan于1993年提出了ID3的改進的方法——C4.5。與ID3相比,C4.5主要在以下幾個方面作了修改,并且引進了新的功能:用信息增益比率作為選擇標準,彌補了ID3算法偏向于取值較多的屬性的不足;合并連續屬性的值;可以處理具有缺少屬性值的訓練樣本;運用不同的剪枝技術來避免決策樹的過擬合現象;K次交叉驗證等等。”
李部長又問:“徐老師,我們在使用決策樹算法進行分類時,有時會出現過擬合現象,這是怎么回事呢?”
徐教授不厭其煩:“基本的決策樹構造算法沒有考慮噪聲,因此生成的決策樹可以完全與訓練數據擬合,也就是說,對訓練數據的測試準確度可以達到100%。但是在有噪聲的情況下,完全擬合將導致“過擬合”的結果,即對訓練數據的完全擬合反而導致對新數據的預測能力下降。這是因為當訓練數據集合包含噪聲時,決策樹在生成的過程中為了與訓練數據一致,必然生成了一些反映噪聲的分支,這些分支不僅在新的決策問題中導致錯誤的預測,而且增加了模型的復雜度。”
馬處長也問道:“那怎么避免過擬合現象呢?”
徐教授:“解決決策樹生成過程中的過擬合問題的方法主要是對決策樹進行剪枝。剪枝是一種克服噪聲的技術,它有助于提高決策樹對新數據的準確分類能力,同時能使決策樹得到簡化,使其更容易理解,加快分類速度。剪枝策略可分為預剪枝(pre-pruning)和后剪枝(post-pruning)兩種。預剪枝主要是通過建立某些規則限制決策樹的充分生長,后剪枝則是等決策樹充分生長完畢后再剪去那些不具有一般代表性的葉節點或者分枝。盡管前一種方法可能看起來更直接,但是后一種方法在實踐中更成功。因此在實際運用中更多的采用的是后剪枝技術。”





























 Tempo商業智能平臺
Tempo商業智能平臺 Tempo人工智能平臺
Tempo人工智能平臺 Tempo數據工廠平臺
Tempo數據工廠平臺 Tempo指標平臺
Tempo指標平臺 Tempo數據治理平臺
Tempo數據治理平臺 Tempo主數據管理平臺
Tempo主數據管理平臺








 陜公網安備 61019002000171號
陜公網安備 61019002000171號



