解碼數據集成效率提升難題,TempoDF給您新思路
2022-01-17 11:50:01
次
數據湖、數據倉庫、湖倉一體、數據中臺……關注大數據領域的人,近期一定常常被這些關鍵詞刷屏,這無疑反應了當下企業級數據集成服務需求的旺盛。
小T觀察到,不少企業隨著自身業務的不斷擴大,各個部門的日常運轉需要的數據量和數據類型也隨之變多,同時自身也會持續不斷產出數據,面對時刻更新的海量數據,企業數據開發團隊如果沒有做好統一協調管理,那么處在大數據之下的每一個人都會像盲人摸象一樣,各自看到的只是大數據的一部分而不是一個整體,導致部門間的協同效率越來越低。
因此,在企業整體數字化轉型的規劃中,數據集成的必要性不言而喻。數據集成顧名思義,指的就是將企業原本分散的各個業務數據系統中的數據進行再集中的過程,它作為各類數據項目的基礎,是連接用戶原始數據與數據治理、數據分析關鍵步驟,也是傳統數據挖掘分析項目執行中容易出現問題的一道環節。
那么從提高整體數據分析項目執行開發效率和開發質量的角度考慮,我們應該如何找到優化數據集成流程的突破口呢?
數據同步效率,影響數據集成質量的關鍵因素
針對于大部分企業的數據集成需求,數據集成可基本分為離線數據同步和實時數據同步兩大類別。
其中最常見的是離線數據同步,其應用場景可以簡單概括為:一個數據源對應一個數據目的地。數據目的地可以是個數據倉庫,將關系型數據庫的數據同步到數據倉庫里,就形成了一次數據集成。
而實時數據同步可以將源端數據庫表的數據變化實時同步至目標數據庫中,實現目標庫實時保持和源庫的數據對應。
但無論是那一種數據集成類型,在傳統以編碼方式實現的數據集成流程中,只要數據量達到一定量級,數據同步效率偏低的問題就會隨之出現。這是因為在企業級數據挖掘分析項目中,數據往往存在于各個部門獨立的數據系統之中,這些小系統互不連通形成了“數據孤島” ,需要抽調數據時還需要根據具體需求單獨抽調技術人員處理,不僅處理成本高,處理時間長,海量數據帶來的數據計算壓力還常常會使數據遷移過程頻繁出現問題,對項目整體數據質量造成影響。
針對數據同步效率低的問題,在Tempo DF中,我們通過3個方面的功能設計去幫助企業優化數據同步工作:
速度
高性能計算引擎保證海量數據高效遷移
在企業級海量數據集成和遷移需求的實現過程中,大家一般最為重視的問題就是數據遷移的快速和穩定問題。
在數據遷移速度方面,TempoDF產品已驗證在集群環境下MySQL至Hive遷移速度可達190000條/s、非結構化文件FTP至HDFS遷移可達150~160M/s。現階段已落地項目均實現流程穩定運行,能夠充分滿足企業級數據倉庫、數據湖項目的數據遷移需求。
簡便
統一編排、調度、管控流程降低運維成本
要想提高數據同步效率,除了提高數據遷移的速度,我們還可以通過簡化合并相關工作任務來加快項目完成時間。
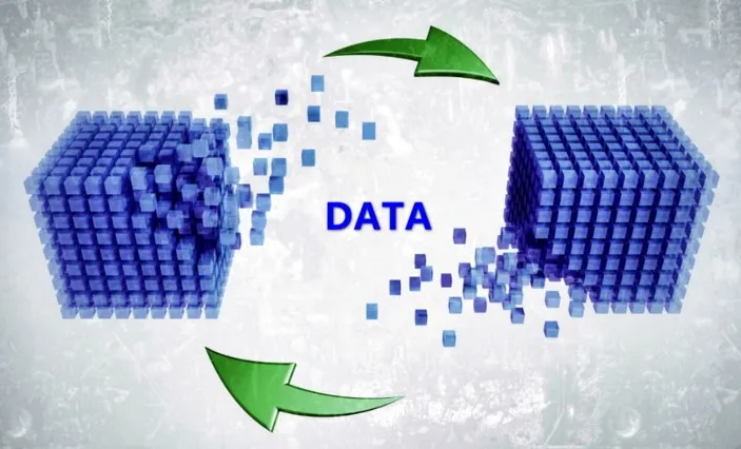
Tempo DF中的作業編排能力和調度、運維功能,能夠將所有的遷移任務便捷集中進行,粒度可細致到每個結構化/非結構化數據的遷移全部按照實際需求設置。
同時支持應用流程發布和管理,方便管理員根據實際情況最大限度提升流程執行效率。當某個同步任務出現問題,僅終止相關業務數據流程,其他遷移任務正常運行。問題修正后可重新補數。讓數據遷移更貼合實際業務。
智能
便捷配置數據遷移任務
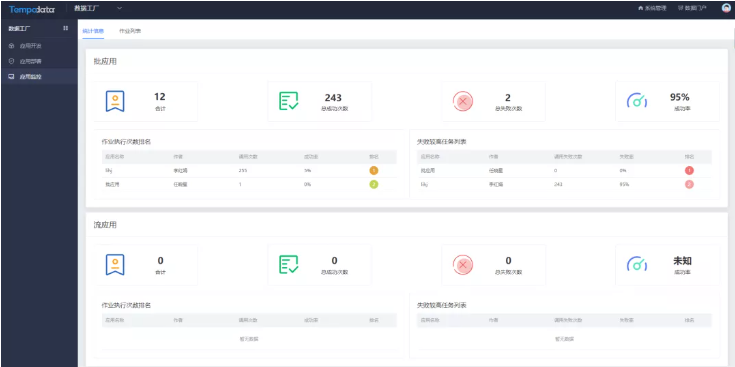
由于數據集成類工作常常牽扯到多個業務系統的數據,在傳統的處理流程中,涉及到的編碼工作量往往非常巨大。而Tempo DF中的設計器工具,可將復雜的數據遷移開發流程簡化為拖拽選擇式的操作,以低代碼的智能操作幫助技術人員節省工作時間,提高工作效率。
通過TempoDF的協助,數據開發工程師在處理數據表遷移任務時,無需再進行額外的編碼工作,只需要通過在設計器中配置數據來源、數據目標,并快速確認兩個異構庫之間的數據類型映射,就可以輕松完成任務。同時可配置遷移過程中的數據處理、資源參數、流量參數和臟數據內容。實現結構化、非結構化數據的全量遷移、增量遷移。
傳統的企業數字化升級改造流程,往往局限于單個業務之中,忽視了企業內部多業務的關聯數據,缺乏對數據的深度理解,導致企業明明投入了大量成本,卻難以真正發揮數據資產的寶貴價值。
因此在數字經濟時代,企業如果想要真正實現數字化轉型,就必須要重視數據集成的實施,通過連通全域數據,建設提純加工后的標準數據資產體系,滿足不斷增長的企業業務對數據的需求。
美林數據Tempo DF平臺就是這樣一款能夠提供成熟海量數據集成方案,完成海量數據分析決策第一步的產品。從此開發實施人員不必每日再為底層數據中斷異常而焦頭爛額,快速實現海量數據高效流轉,直接提升項目交付效率、解決企業海量數據集成難題,為用戶后續各項數據分析工作打好堅實基礎。
如果想要體驗更加高效便捷的數據集成實施方式,歡迎申請試用~





























 Tempo商業智能平臺
Tempo商業智能平臺 Tempo人工智能平臺
Tempo人工智能平臺 Tempo數據工廠平臺
Tempo數據工廠平臺 Tempo指標平臺
Tempo指標平臺 Tempo數據治理平臺
Tempo數據治理平臺 Tempo主數據管理平臺
Tempo主數據管理平臺










 陜公網安備 61019002000171號
陜公網安備 61019002000171號



