數據孤島怎么辦?你的企業數據需要數據集成平臺
2022-09-06 16:00:30
次
在企業中,業務的快速發展產生了大量數據,也出現了多種應用系統,各系統承載不同類型的數據,并對應著不同的數據存儲方式。這些系統的數據源彼此獨立、相互封閉,使得數據難以在系統直接交流、共享和融合,從而形成了“數據孤島”。
在進行企業級數據挖掘分析項目中,要先將企業內部各個業務系統的數據實現互聯互通,從物理上打破數據孤島,而這就需要通過數據集成來實現。
數據集成概念
數據集成:從字面上來說是企業獨立的信息系統之間的數據。在很多應用場合,人們需要整合不同來源的數據,才能獲取有效的分析結果,否則,不完整的數據將導致分析結果不準確。數據集成將若干個分散的數據源中的數據,邏輯地或物理地集成到一個統一的數據集合中。
數據集成就是將若干個分散的數據源中的數據,邏輯地或物理地集成到一個統一的數據集合中。數據集成的核心任務是要將互相關聯的分布式異構數據源集成到一起,使用戶能夠以透明的方式訪問這些數據源。集成是指維護數據源整體上的數據一致性、提高信息共享利用的效率;透明的方式是指用戶無需關心如何實現對異構數據源數據的訪問,只關心以何種方式訪問何種數據。實現數據集成的系統稱作數據集成系統,它為用戶提供統一的數據源訪問接口,執行用戶對數據源的訪問請求。
結構化數據、非結構化數據、半結構化數據
下面讓我們來了解一下數據都分為哪些結構:
1、結構化數據
簡單說就是數據庫,也稱作為行數據,是由二維表結構來邏輯表達和實現的數據,嚴格地遵循數據格式與長度規范,主要通過關系型數據庫進行存儲和管理。
2、半結構化數據
非關系模型的、有基本固定結構模式的數據,但和具有嚴格理論模型的關系數據庫的數據相比,更靈活。包含在兩個或多個數據庫中的數據。
半結構化數據可以通過靈活的鍵值調整,獲取相應信息,且數據的格式不固定,例如日志文件、XML文檔、JSON文檔、Email等。
3、非結構化數據
非結構化數據是數據結構不規則或不完整,沒有預定義的數據模型,不方便用數據庫二維邏輯表來表現的數據。包括所有格式的辦公文檔、文本、圖片、各類報表、圖像和音頻/視頻信息等等。
為什么要做數據集成
⇒打破數據孤島,降低數據處理成本;
⇒減少數據處理時間,提高響應速度;
⇒減少海量數據計算壓力導致數據遷移過程出現問題次數;
⇒提高項目整體數據質量;
⇒高穩定性:平臺采用集群架構搭建,保證平臺功能穩定,同時對集成場景進行多方位的異常處理,保證接口運行的穩定,為企業提供穩定的集成平臺。
⇒高性能性:TempoDF產品已驗證在集群環境下MySQL至Hive遷移速度可達190000條/s、非結構化文件FTP至HDFS遷移可達150~160M/s;
⇒流批一體:支持實時數據和離線數據集成;
⇒多模式:支持全量、增量等模式;
⇒可追溯:數據血緣可查詢、監控預警等。
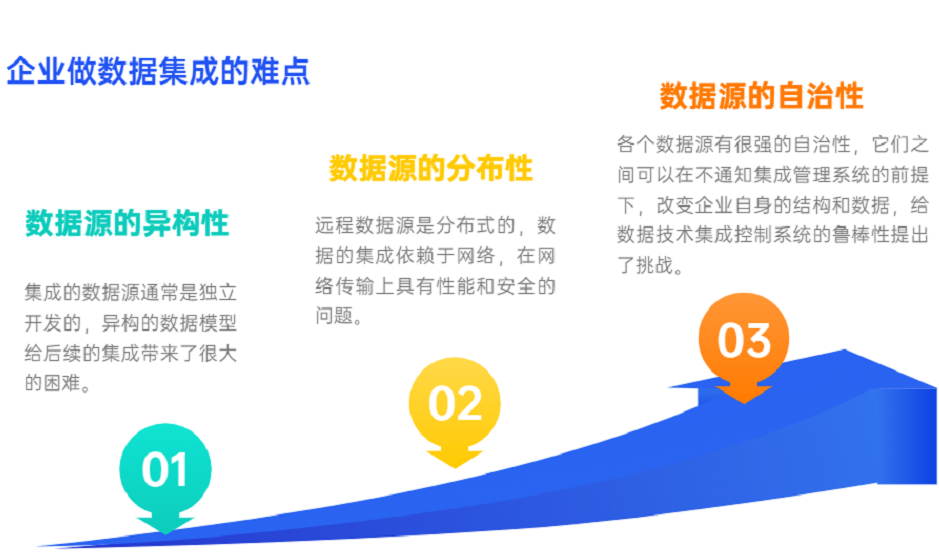
且跨系統的數據標準不一致,在進行跨系統的數據打通、流程打通時問題顯著。
TempoDF數據集成價值
⇒企業多系統集成
企業的應用系統多,不同的IT系統形成了信息孤島。
⇒多源異構數據快速融合
來自多個數據源,不同的數據源所在的操作系統、管理系統不同,數據的存儲模式和邏輯結構不同,數據的產生時間、使用場所、代碼協議等也不同.
Tempo DF平臺能夠提供成熟海量數據集成方案,完成海量數據分析決策第一步的產品。從此開發實施人員不必每日再為底層數據中斷異常而焦頭爛額,快速實現海量數據高效流轉,直接提升項目交付效率、解決企業海量數據集成難題,為用戶后續各項數據分析工作打好堅實基礎。





























 Tempo商業智能平臺
Tempo商業智能平臺 Tempo人工智能平臺
Tempo人工智能平臺 Tempo數據工廠平臺
Tempo數據工廠平臺 Tempo指標平臺
Tempo指標平臺 Tempo數據治理平臺
Tempo數據治理平臺 Tempo主數據管理平臺
Tempo主數據管理平臺








 陜公網安備 61019002000171號
陜公網安備 61019002000171號



