Spark讀取kafka復雜嵌套json的最佳實踐,與其在大數據分析平臺中的應用
2022-09-16 18:54:00
次
隨著互聯網的更進一步發展,信息瀏覽、搜索以及電子商務、互聯網旅游生活產品等將生活中的流通環節在線化,對于實時性的要求進一步提升,而信息的交互和溝通正在從點對點往信息鏈甚至信息網的方向發展,這樣必然帶來數據各個維度的交叉關聯,數據爆炸也不可避免,因此流式處理應運而生,解決實時框架問題,助力大數據分析。
kafka是一個高性能的流式消息隊列,適用于大數據場景下的消息傳輸、消息處理和消息存儲,kafka可靠的傳遞能力讓它成為流式處理系統完美的數據來源,很多基于kafka構建的流式處理系統都將kafka作為唯一可靠的數據來源。如Apache Storm、 Apache Spark Streaming 、Apache Flink 、Apache Samza 等。
json是kafka消息中比較常見的格式,對于單層json數據的讀取和解析相對簡單,但是在真實kafka流程處理的業務中,很多情況下都是json嵌套復雜格式消息。Spark1.1以后的版本存在一些實用的 SparkSQL函數,幫助解決復雜的json數據格式,實用函數包括get_json_object、from_json和explode等。
01、Spark框架中的基本概念和內置函數
? RDD:Spark的基本計算單元,它是一個彈性可復原的分布式數據集。
? Dataframe:定義為指定到列的數據集(Dataset)。DFS類似于關系型數據庫中的表或者像R/Python 中的Dataframe ,可以說是一個具有良好優化技術的關系表。
? Spark SQL:它是Spark的其中一個模塊,用于結構化數據處理,Spark SQL提供的接口為Spark提供了有關數據結構和正在執行的計算的更多信息,Spark SQL會使用這些額外的信息來執行額外的優化。
? from_json:Spark SQL內置的函數,從一個json 字符串中按照指定的schema格式抽取出來作為DataFrame的列,第一個參數為列名,以$"column_name"表示,第二個參數為定義的數據結構
? get_json_object:Spark SQL內置的函數,從一個json字符串中根據指定的json路徑抽取一個json對象,第一個參數為column名,用$"column_name"表示,第二個參數為要取的json字段名,"$.字段名"表示。
? explode:Spark SQL內置的函數,可以從規定的Array或者Map中使用每一個元素創建一列,主要用于數組數據的展開,參數為column名,用$"column_name"表示。
02、Kafka復雜嵌套json解析
1)什么是復雜json?
json是一種輕量級的數據交換標準,具體以逗號分隔的key:value鍵值對的串形式,主要表現形式包括兩種:{對象},[數組],其中key以字符串表達,value包括字符串、數值、boolean值、對象和數組(可嵌套)。在復雜的json數據格式中,通常json數據會有嵌套,每個層級的結構不完全相同,value中不同類型進行混合使用。
下圖為一份簡單json格式數據:
期望處理的結果為下圖的二維表,json串中的key(id,sepallength,sepalwidth,
petallength,petalwidth,label)作為二維表的列,value作為表的一行數據。
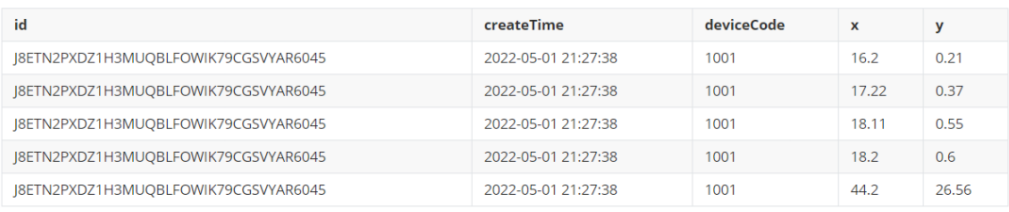
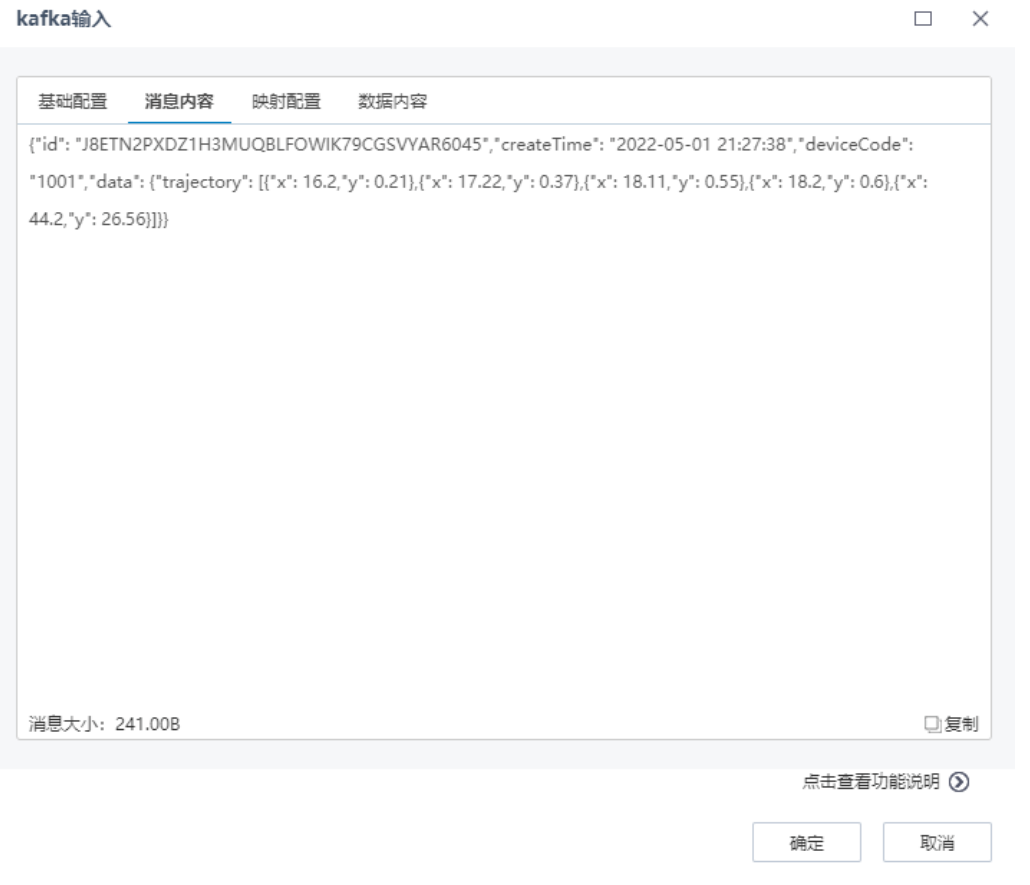
下圖為一份復雜json格式數據:
期望處理的結果為下圖的二維表,json串中單層key(id,createTime,deviceCode)和需要展開的數組trajectory中單個元素key(x,y)作為二維表的列,value是將數組trajectory中所有的元素展開成多行后,與其他列的數據進行對齊。
2)整體思路
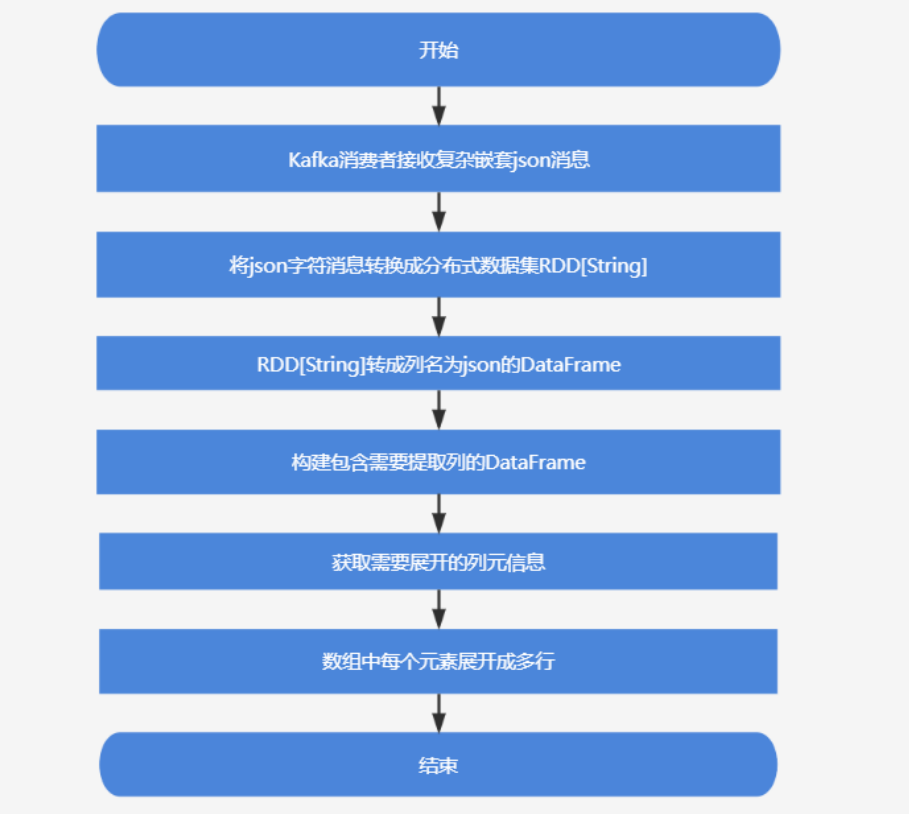
Kafka消費者收到復雜嵌套json消息后,一共有兩步。
第一步:首先把這批json字符消息轉換成分布式數據集RDD[String]中,再將RDD[String]轉換成列名為`json`的DataFrame,然后通過Spark SQL內置函數get_json_object將json對象中的`id`、`createTime`、`deviceCode`、`data.trajectory`分別生成新列,并構建一個包含這些列的新DataFrame;
第二步:獲取需要展開的列`data.trajectory`的schema(元數據信息),然后由SparkSQL內置函數from_json將列`data.trajectory`的字符內容轉換成數組對象,最后通過SparkSQL內置函數explode將`data.trajectory`中的數組中每個元素展開成多行。
基于spark解析復雜json流程設計圖:
3)Spark讀取kafka復雜json消息解析核心代碼
json格式數據如果使用現有的工具,用戶常常需要開發出復雜的程序來讀寫分析系統中的json數據,Spark SQL對json數據的支持是從1.1版本開始發布,并且在Spark 1.2版本中進行了加強。
下圖的代碼是通過Spark SQL內置的json函數將復雜json轉換成一張二維表,并支持將json中數組數據進行展開處理。
4)kafka復雜json解析在Tempo AI中的應用
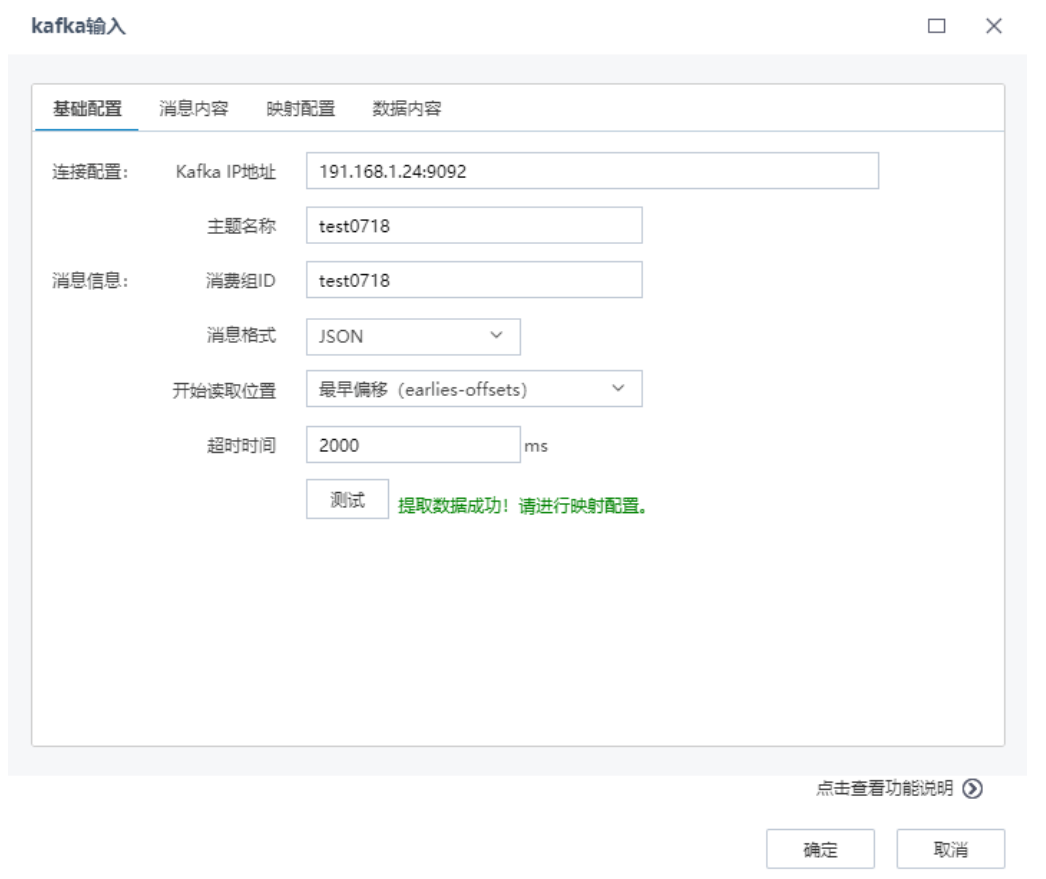
Tempo AI機器學習平臺將kafka數據作為數據挖掘分析標準數據源,既支持簡單的json解析,也支持復雜json解析,先進行基礎配置讀取消息數據,查看消息內容,然后進行映射配置,將數據內容與對應元信息進行匹配,最后可以預覽數據內容。
基礎配置,包括連接配置和消息信息配置,如下圖所示:
在“消息內容”頁面,查看提取的單條Kafka消息內容,如下圖:
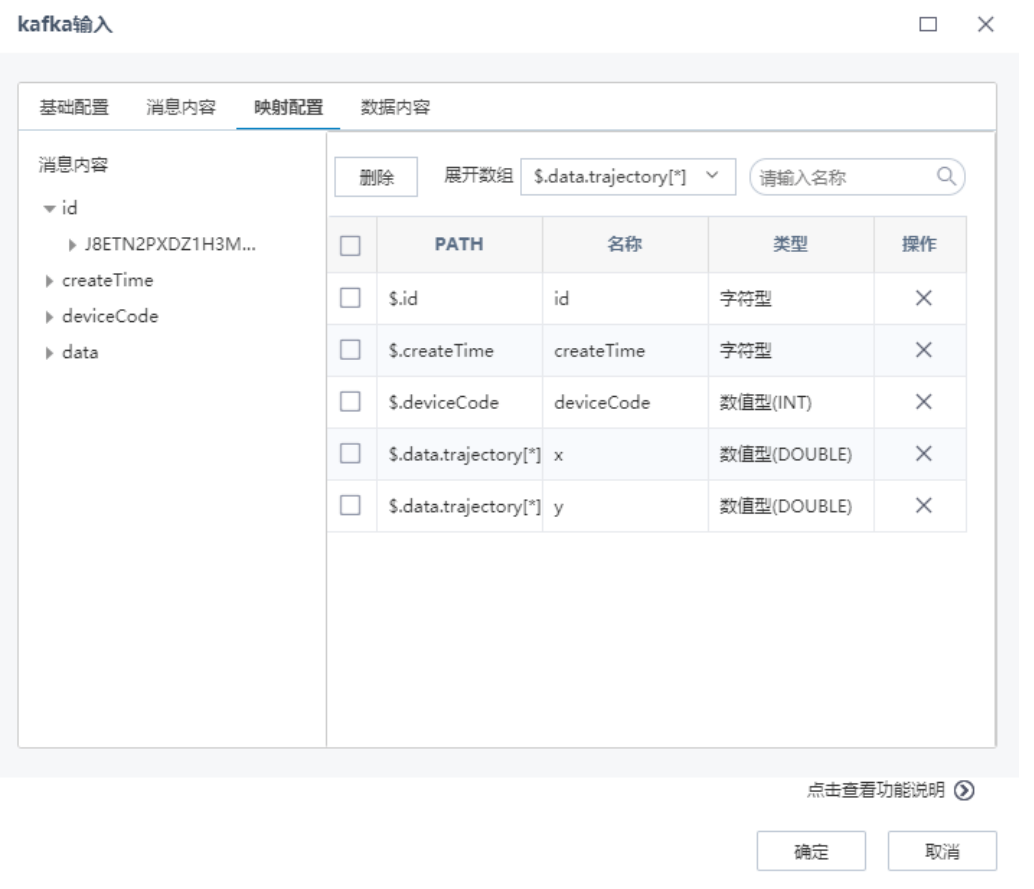
在“映射配置”頁面,根據左側預覽的消息內容,通過點擊選擇左側的消息到右側,進行映射配置,可以設置需要展開的數組,如下圖:
kafka輸入節點配置完成后,執行AI流程,查看洞察信息,如下圖所示:
綜上,json是一種輕量級的數據交換格式,易于閱讀和編寫,目前是一種主流的數據格式,json字符串作為消息在kafka消息流中傳遞應用很廣泛,通過Tempo 機器學習平臺封裝的Spark SQL解析復雜json的能力,極大簡化了使用json數據的終端的相關工作,使客戶更專注于自己的業務。





























 Tempo商業智能平臺
Tempo商業智能平臺 Tempo人工智能平臺
Tempo人工智能平臺 Tempo數據工廠平臺
Tempo數據工廠平臺 Tempo指標平臺
Tempo指標平臺 Tempo數據治理平臺
Tempo數據治理平臺 Tempo主數據管理平臺
Tempo主數據管理平臺
















 陜公網安備 61019002000171號
陜公網安備 61019002000171號



