




























 Tempo商業智能平臺
Tempo商業智能平臺 Tempo人工智能平臺
Tempo人工智能平臺 Tempo數據工廠平臺
Tempo數據工廠平臺 Tempo指標平臺
Tempo指標平臺 Tempo數據治理平臺
Tempo數據治理平臺 Tempo主數據管理平臺
Tempo主數據管理平臺




服務熱線
400-608-2558
咨詢熱線
15502965860-


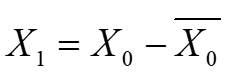
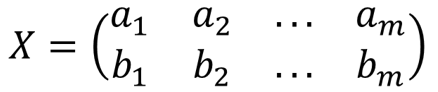
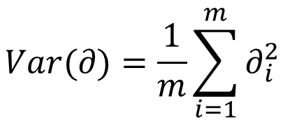
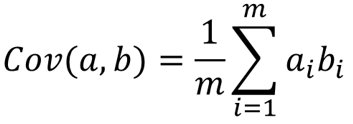
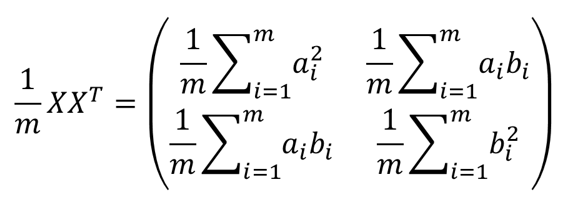
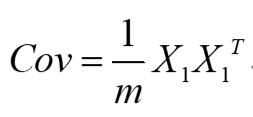
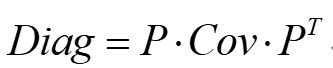
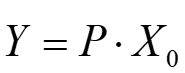
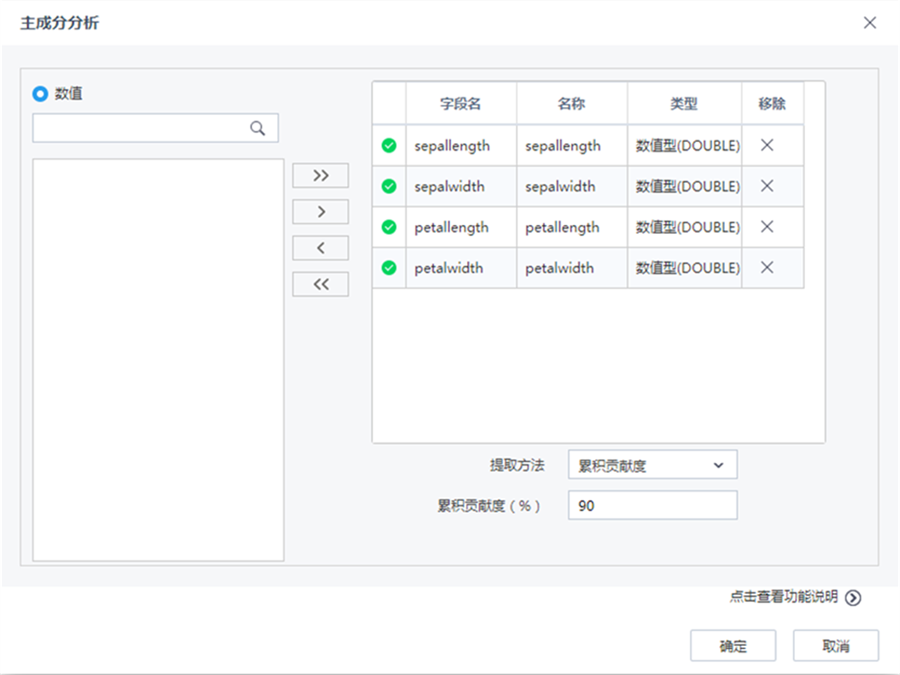
| 參數 | 類型 | 描述 |
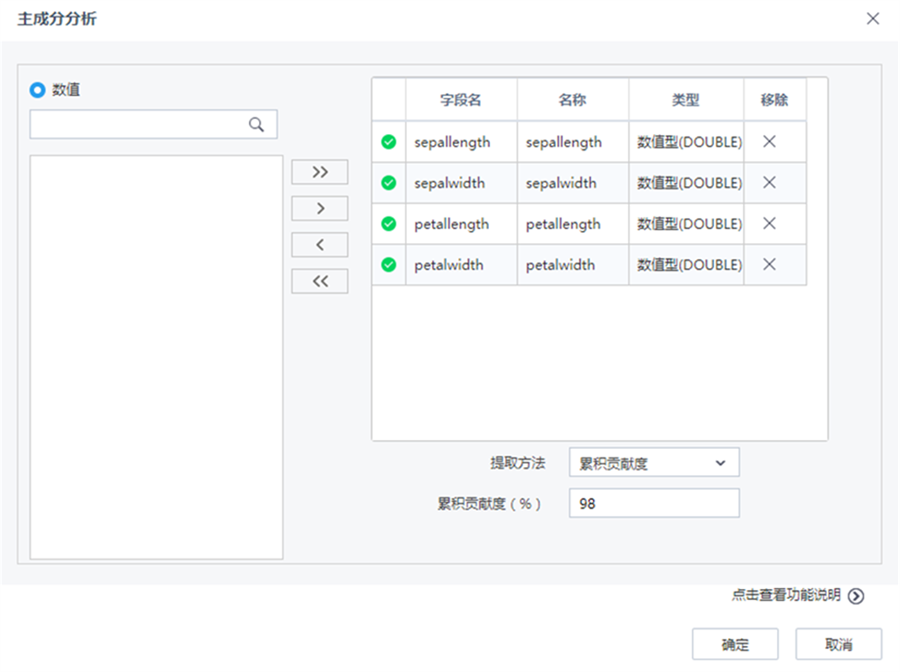
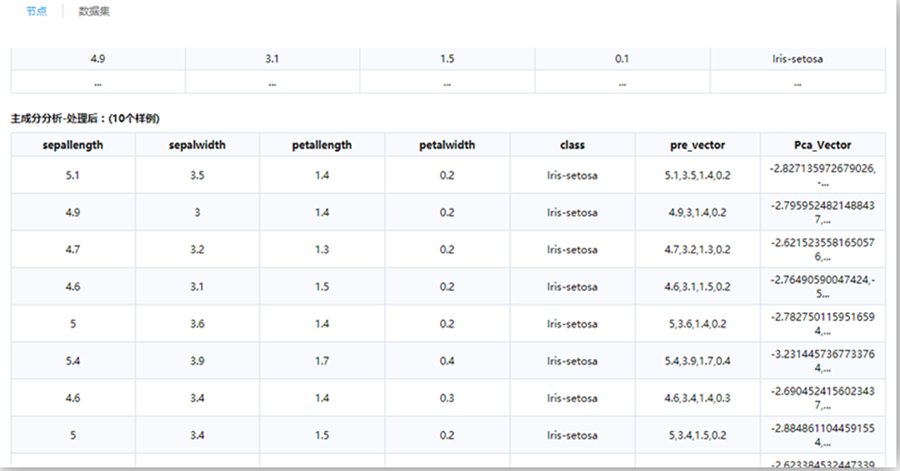
| 選擇變量 | 列表框 | 用戶指定需要進行主成分分析的屬性列,需要指定大于1個的變量作為主成分分析的對象 |
| 提取方法 | 下拉框 | 按照因子數、累積貢獻度的方式進行主成分分析。 |
| 因子數 | 文本框 | 當提取方法為因子數時,用戶直接指定需要分解的因子數。默認為1。 |
| 累積貢獻度 | 文本框 | 當提取方法為累積貢獻度時,用戶直接指定需要貢獻度的大小。默認為90%。 |
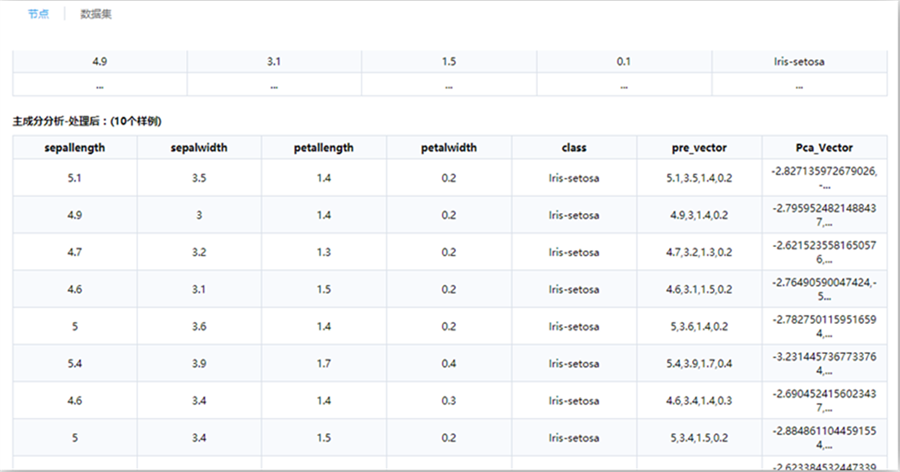

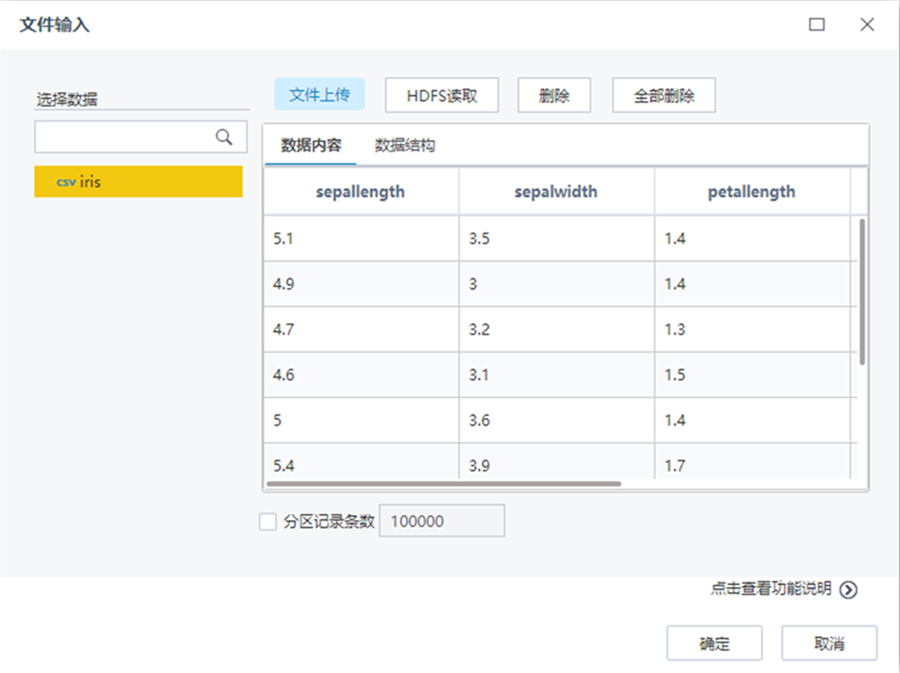
全國服務電話:
企業郵箱:tempo@meritdata.com.cn
地址:中國西安 ? 雁塔區西三環天谷八路軟件新城國家電子商務示范基地六層


 陜公網安備 61019002000171號
陜公網安備 61019002000171號



