數據分析工具選Python還是Scala?我們幫你解決選擇困難癥
2022-09-26 09:51:00
次
做數據分析時,如果需要編程,會面臨一個數據分析工具選擇的問題:選擇Scala,還是Python?
一般給的建議是小數據用Python,大數據用Scala,當然是基于Spark平臺的Scala,因為JVM的加持,Scala的性能相較于Python快10倍,Scala是函數式編程語言,主打簡潔、性能;python主打過程式,易用、膠水,生態完整,是AI時代的御用語言,而且可以使用的數據處理基礎庫比較多,最流行的當然是Pandas。
先說下歷史, 圖靈,不但完成了二戰密碼破解任務,而且是計算機理論的奠基者,解決世紀數學難題的同時完成了那篇著名的論文《On Computable Numbers with an Application to the Entscheidungs-problem》,論文中定義的圖靈機中僅僅一條紙帶,一個讀寫頭,就可以完成所有計算問題,現在的所有計算機都可以抽象為圖靈機,圖靈機也是所有過程式編程語言的基礎理論依據,因為圖靈機更接近現實世界,更容易實現,因此在一段時間內,全部都是過程式編程語言。
但是,一場天才之間的相遇,丘齊當上了圖靈的老師,一場思想的碰撞,邱齊的 lambda算子(λ)橫空出世,只用最簡潔的幾條公理便建立起了與圖靈機完全等價的計算模型,掀開了函數編程語言的時代,先后出現了Lisp 、 Scheme 、 Haskell這些以抽象性和簡潔美為主旨的語言。
函數式編程簡潔但是不簡單,學習曲線陡峭且比較難于進行性能優化,因此Scala兼采兩家之長,支持函數式,構建于Java生態,復用了目前Java生態的所有成果,并且保證了程序執行速度,做到了“高效、廣譜”,既可以面向對象,過程式編程,降低程序優化難度,又可以使用函數式編程,保證程序的簡潔性。Spark 平臺1.0版的核心代碼只有4萬行,Scala語言的簡潔和豐富的表達力起到了關鍵作用。
該如何選擇?
對我們來說,在多個語言間選擇數據分析工具一般要考慮3個因素:
? 生態:是否有成熟的函數庫,能否通過已經掌握的編程語言快速過渡?
? 性能:性能如何,在有些情況下是關鍵決策項?
? 簡潔:語言是否簡潔,能否能夠快速驗證我們的想法,實現“所見即所得”
01、生態
我們先分析下第一點,從下圖我們可以看到,使用Scala可以直接使用DataFrame,而DataFrame的功能和Pandas完全相同,并進一步增加了分布式的能力,能應對海量數據的處理,所以Scala生態有特別成熟的函數庫。
既然Scala又好又快為什么不直接用Scala做數據分析,還要用Python?
前面提到,函數式編程語言簡潔但是不簡單,學習曲線陡峭,既然Scala定位是函數式編程語言,因此也難逃此定律。使用Python實現數據統計,程序容易開發,容易遷移,可快速驗證想法。
大部分數據分析師都掌握Python,并且基本都會使用Pandas,因此實際應用中Python是首選。而基于Scala語言的Spark平臺也有和Pandas對應的基礎框架DataFrame,且Pandas和DataFrame之間的函數功能相似度極高,因此我們也可以基于Python代碼完成對Scala語言的一一比對式學習,讓學習找到著力點,所以,如果你已經掌握Python,此時再學Scala是水到渠成的事。
02、性能
作為一門編程語言,最后都要落地執行,性能是至關重要的一環,性能好意味著時間短,做任何事,時間永遠是最大的成本。
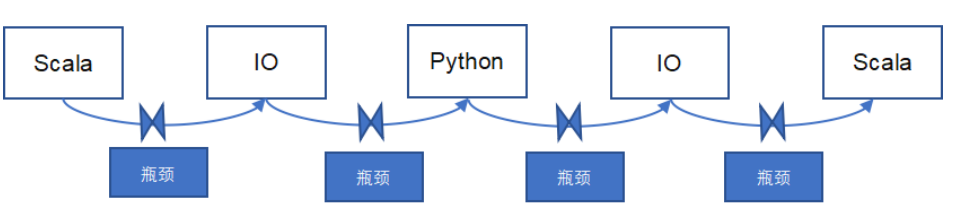
Python有優勢,但是劣勢也相當明顯。除了Python語言本身特點導致其執行速度比Scala本身慢2到3倍外,不同語言開發的應用程序間的IO也往往是性能的關鍵瓶頸點。從下圖可以看出,從Scala到Python處理過程需要經歷兩次IO過程,在數據量較小的情況下,此過程可以順暢執行,但如果數據量較大,那肯定是瓶頸所在。
這個問題怎么解決?
目前有一些折中的方法,例如使用Arrow,基于流水線,完成高效的IO過程,如果你不想折中,我建議使用Scala,Scala語言既擁有面向對象的能力,又具有函數式編程的簡潔和高效,并且和Java語言可天然的“零開銷”集成。
03、簡潔
性能上Scala有天然優勢,那么從代碼的簡潔度上孰優孰劣,能否像Python一樣快速驗證我們的想法?我們從以下幾個從簡單到復雜的場景比對下”區別“。
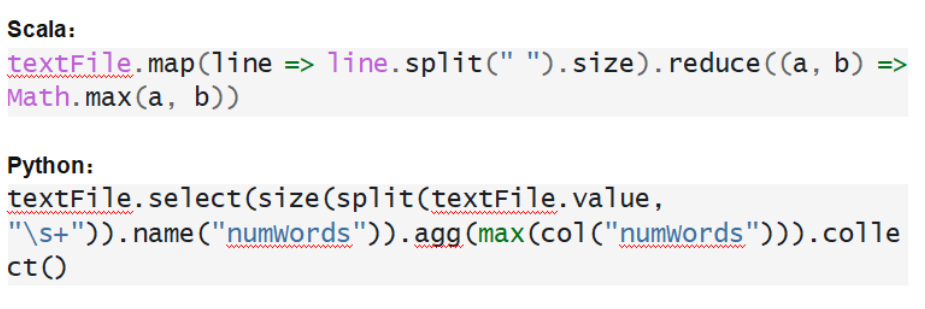
? 第一個場景:字符處理
從最直觀的感受上,這個字符處理場景 Scala略勝一籌。
? 第二個場景:自定義函數
當然,第一個場景只能是演示過程中的用的最直觀的例子,可能在實際生產中的應用不多,那對于一些更專業的技術人員,自定義函數是日常開發中經常要用到的,我們再看看在這個場景誰更簡潔:
從簡潔性上來說,此役平分秋色。
? 第三個場景:Map/Reduce過程
Map/Reduce過程是現今所有分布式大數據處理技術的理論基石,而其中最關鍵的一環是對于鍵值對(Key-Value Pairs)的處理,Scala和python如何處理?
此處也是半斤對八兩。
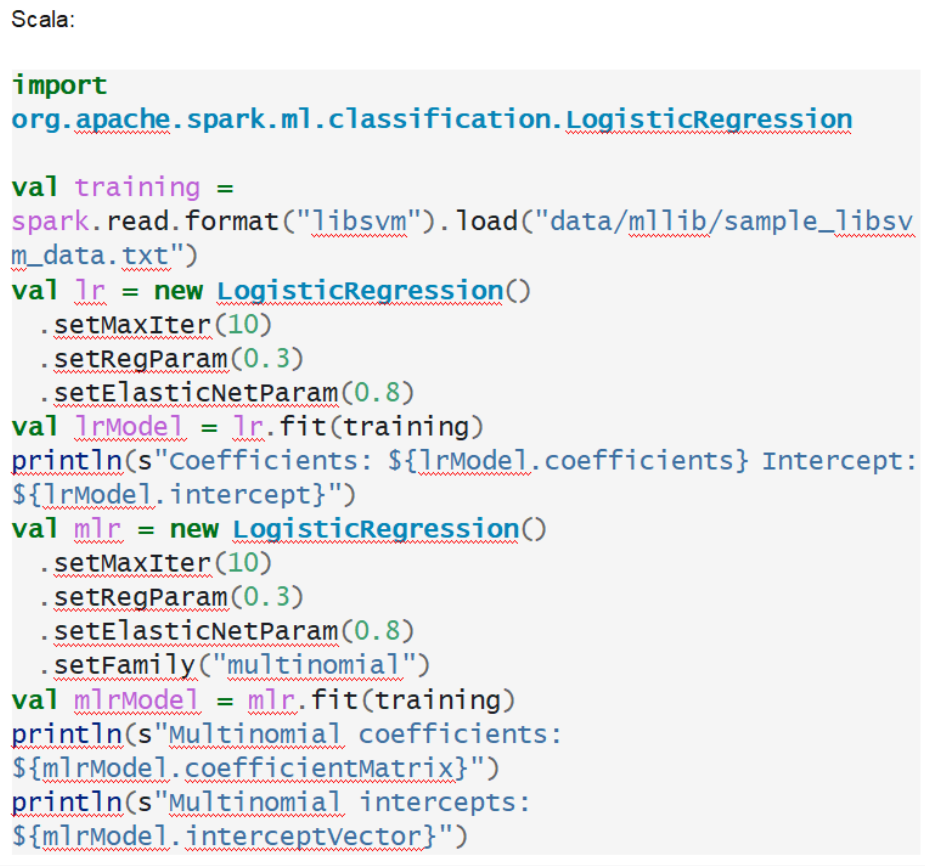
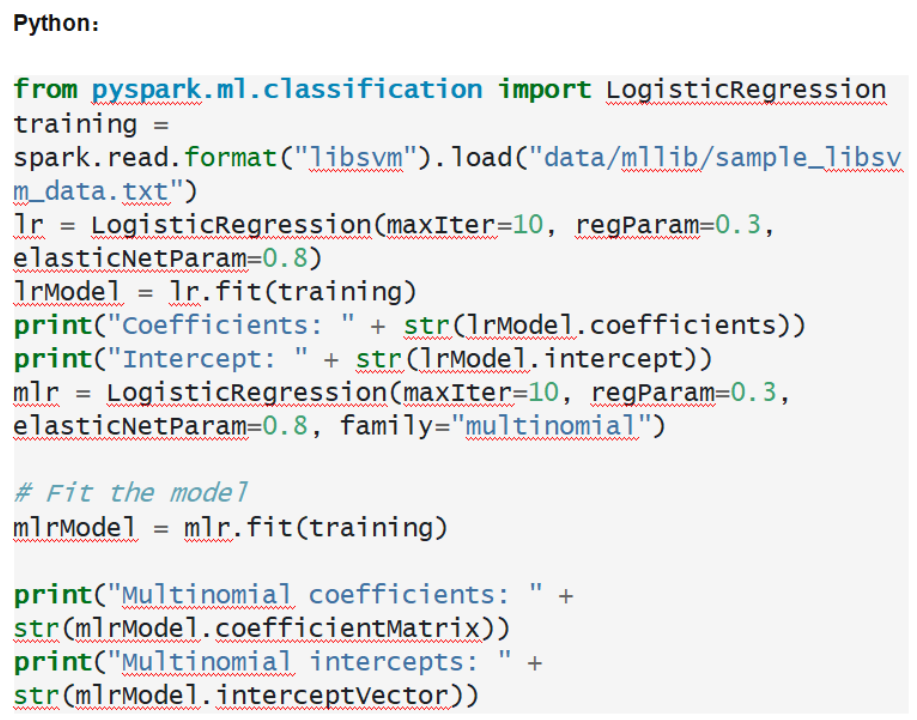
? 第四個場景:數據挖掘算法
做開發不只有簡單場景,我們這里對比下在數據挖掘算法中兩種語言的表現,二項式邏輯回歸(Binomial logistic regression)給您奉上。
可以說是互為鏡像,孿生兄弟。
總結
從過程式到函數式,編程語言經歷了大半個世紀的發展,各個分支都已經趨近成熟,近15年出現的大數據技術的出現讓各種編程語言有的老樹新花,有的找到了新戰場。
函數式編程更適合用在大數據處理技術的場景中,而Scala語言結合過程式的性能,函數式的簡潔,極其強大的生態,以及背后巨大資本力量的推動,無疑是我們學習大數據處理技術的首選語言,如果你是Python開發者,或者Java開發者,都可以輕松成為Scala開發者,快速獲得其性能、簡潔和生態的優勢。





























 Tempo商業智能平臺
Tempo商業智能平臺 Tempo人工智能平臺
Tempo人工智能平臺 Tempo數據工廠平臺
Tempo數據工廠平臺 Tempo指標平臺
Tempo指標平臺 Tempo數據治理平臺
Tempo數據治理平臺 Tempo主數據管理平臺
Tempo主數據管理平臺














 陜公網安備 61019002000171號
陜公網安備 61019002000171號



