




























 Tempo商業智能平臺
Tempo商業智能平臺 Tempo人工智能平臺
Tempo人工智能平臺 Tempo數據工廠平臺
Tempo數據工廠平臺 Tempo指標平臺
Tempo指標平臺 Tempo數據治理平臺
Tempo數據治理平臺 Tempo主數據管理平臺
Tempo主數據管理平臺




服務熱線
400-608-2558
咨詢熱線
15502965860-


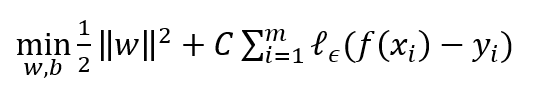
 是 ε-不敏感損失函數:
是 ε-不敏感損失函數:
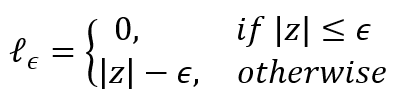
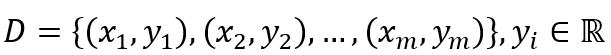 ,選取適當的核函數
,選取適當的核函數 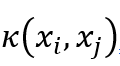 核適當的參數C和適當的精度參數ε,并構造求解最優化問題.
核適當的參數C和適當的精度參數ε,并構造求解最優化問題.
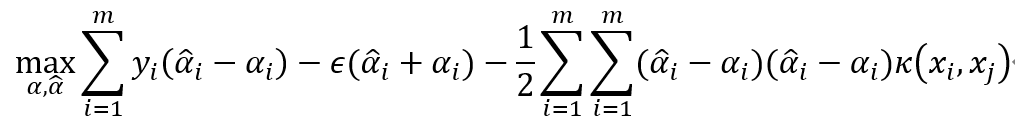
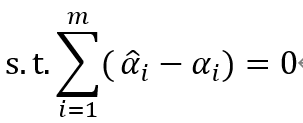
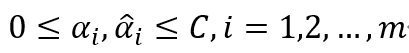
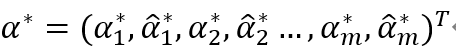
 的一個正分量0<
的一個正分量0<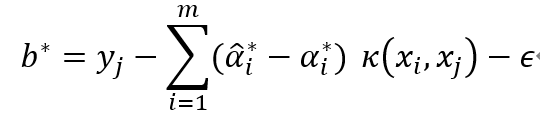
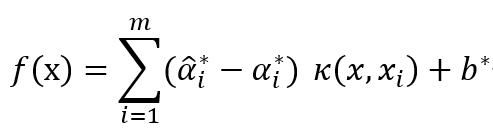
 是正定核函數。
是正定核函數。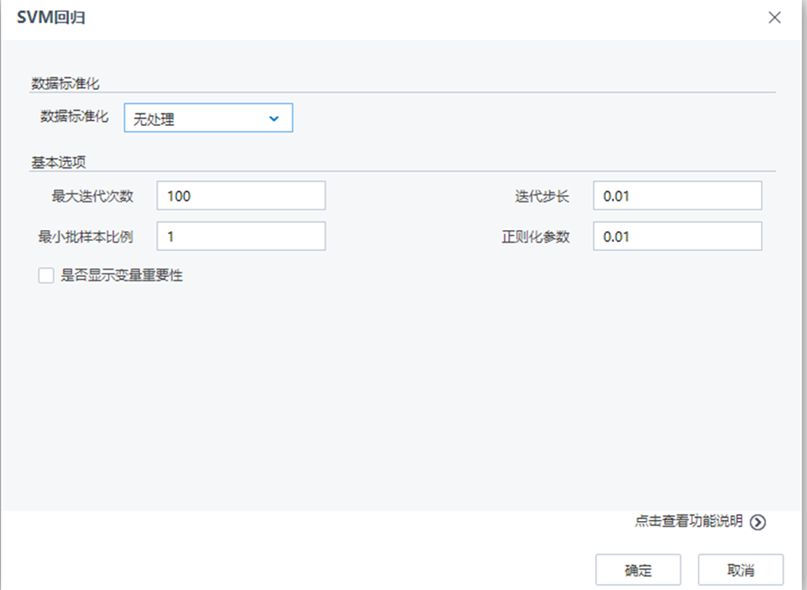
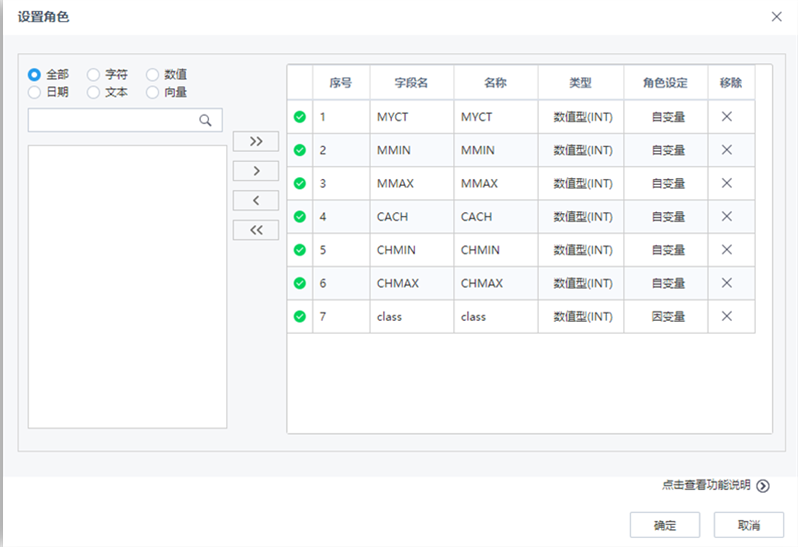
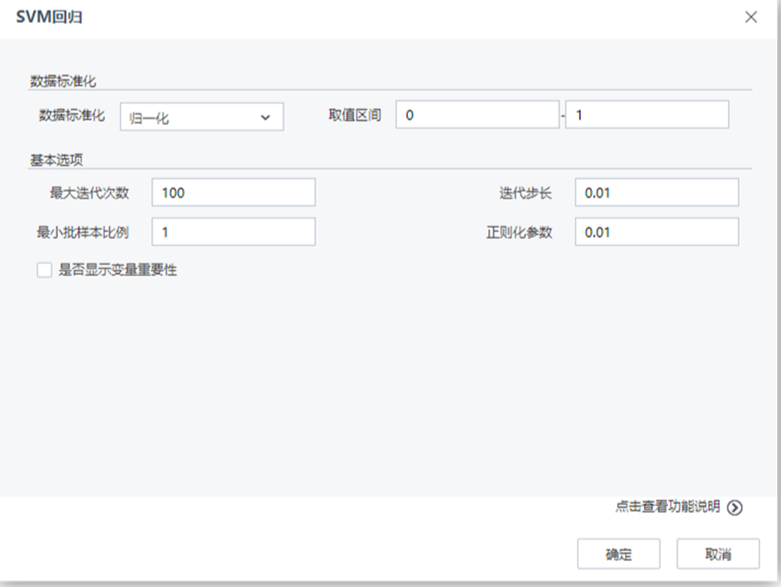
| 參數 | 類型 | 描述 |
| 數據標準化 | 下拉框 | 設置數據標準化的方法,字符型,取值范圍:無處理,歸一化,標準化,默認值為無處理 |
| 取值區間下限 | 文本框 | 設置歸一化取值區間下限,浮點型,取值范圍:[0,∞),默認值為0 |
| 取值區間上限 | 文本框 | 設置歸一化取值區間上限,浮點型,取值范圍:[0,∞),默認值為1 |
| 正則化參數 | 文本框 | 正則化參數控制機器的復雜度,浮點型,取值范圍:[0,∞),默認值為0.01 |
| 迭代步長 | 文本框 | 設置每次迭代的步長,浮點型,取值范圍:(0,∞),默認值為0.01 |
| 最大迭代次數 | 文本框 | 設置最大迭代次數,整型,取值范圍:[1,∞),默認值為100 |
| 最小批樣本比例 | 文本框 | 設置每次迭代的樣本比例,浮點型,取值范圍:(0,1],默認值為1 |
| 是否顯示變量重要性 | 復選框 | 用戶選擇是否分析每個變量對于回歸結果的影響程度,如果選擇是,則在洞察中顯示參與建模的每個變量對于模型的貢獻程度情況 |
全國服務電話:
企業郵箱:tempo@meritdata.com.cn
地址:中國西安 ? 雁塔區西三環天谷八路軟件新城國家電子商務示范基地六層


 陜公網安備 61019002000171號
陜公網安備 61019002000171號



