




























 Tempo商業智能平臺
Tempo商業智能平臺 Tempo人工智能平臺
Tempo人工智能平臺 Tempo數據工廠平臺
Tempo數據工廠平臺 Tempo指標平臺
Tempo指標平臺 Tempo數據治理平臺
Tempo數據治理平臺 Tempo主數據管理平臺
Tempo主數據管理平臺




服務熱線
400-608-2558
咨詢熱線
15502965860-



數據分析需要很多步驟,在整個過程中,數據的預處理往往會占用項目很長的時間,包含清洗、融合、異常值處理等。而作為數據分析的第一步,數據預處理在人工智能的落地實現中是非常重要的一環,這一步的整體質量直接決定了后續建模的準確性,數據越多、訓練模型越復雜,對數據預處理的工作需求量就越大。
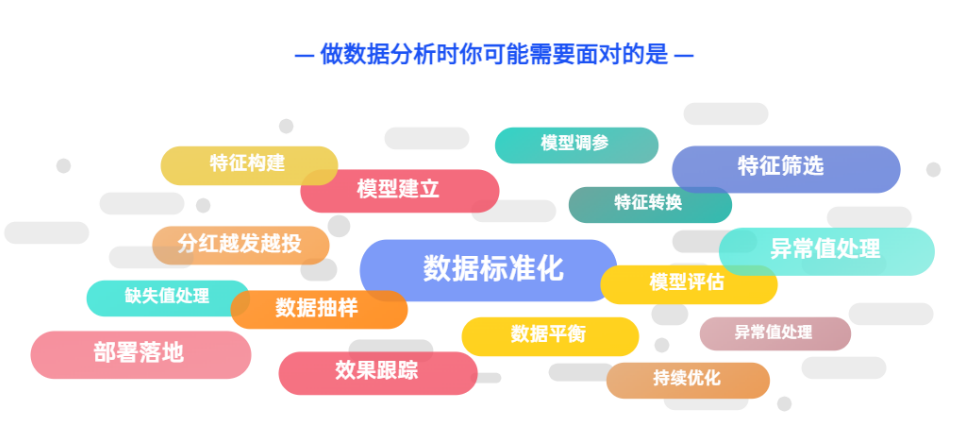
數據預處理的核心工作往往包含了數據融合、異常值處理、數據類型轉換、歸一化、去噪等多個方面,這些都是數據挖掘任務中不可缺少的環節。通過這些處理,可以進一步提高數據的質量,也能讓數據更好地適應特定的挖掘技術或工具。那么,該如何高效完成數據的預處理工作呢?
Tempo機器學習平臺數據預處理解決方案了解下!
01 數據融合
常用場景
數據分析中使用的數據常常來自于不同的數據源,當單張表的內容無法滿足當前的分析需求時,就需要將多張表的數據信息進行關聯,從而展開更為全面的分析與洞察。
Tempo機器學習平臺可以通過簡單的操作,完成不同表之間的數據連接與融合。
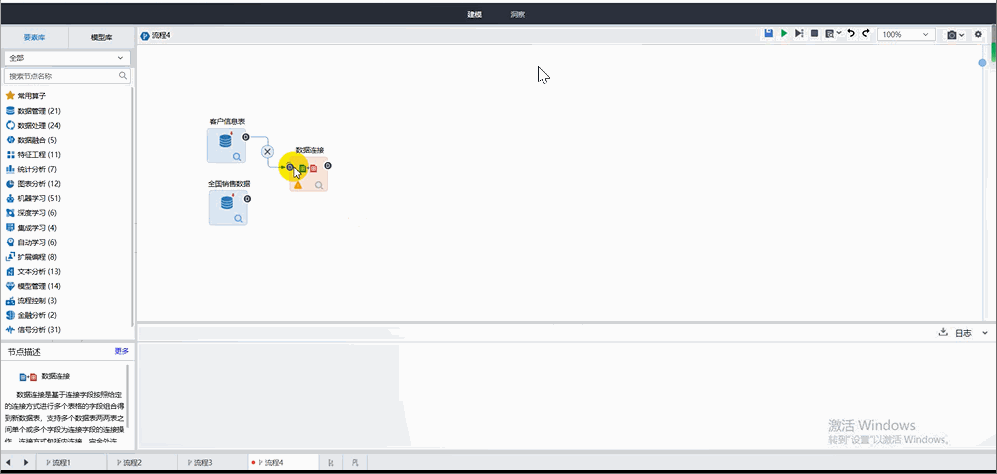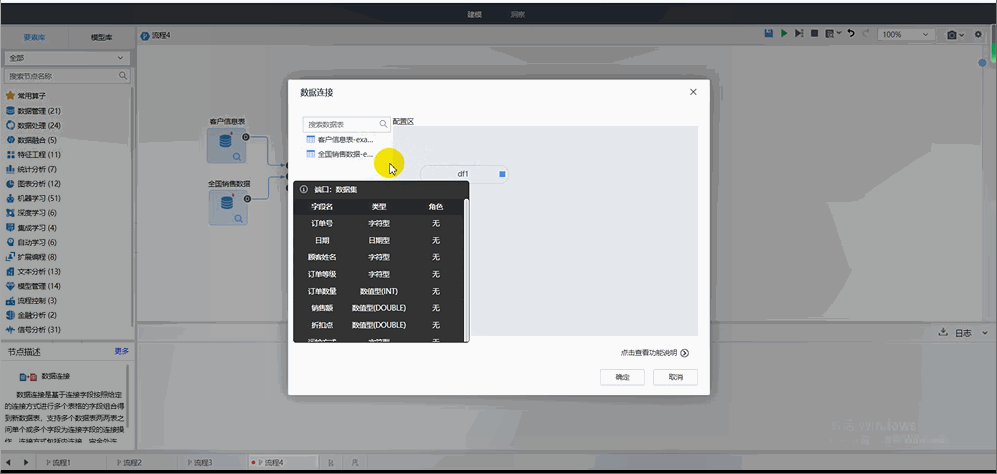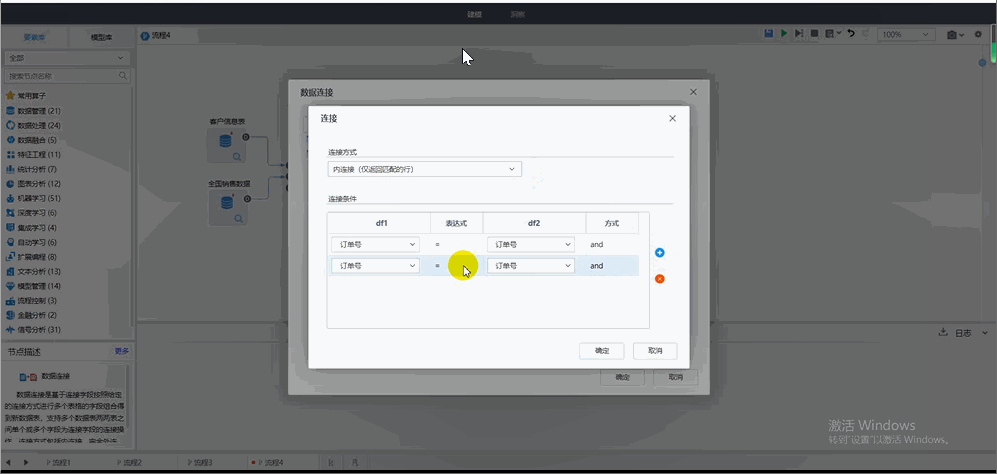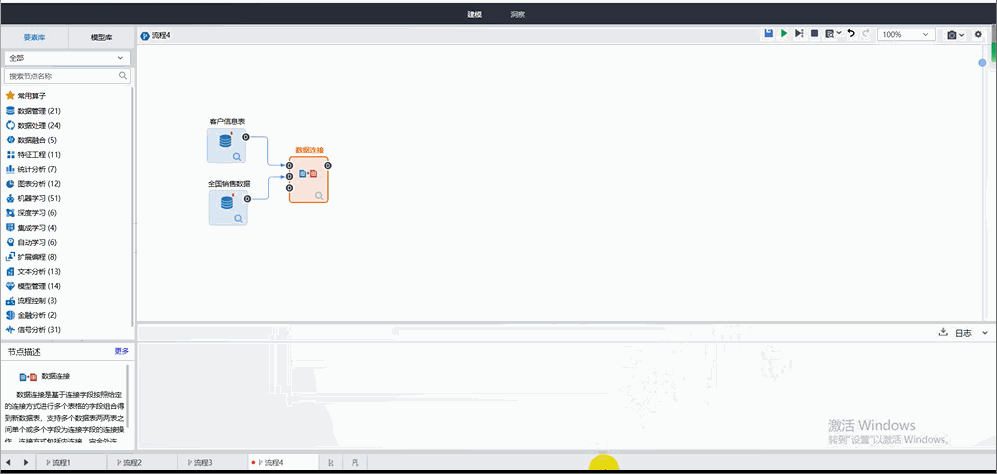
? 融合方式多樣:涵蓋內連接、完全外連接、左連接、右連接4種方式;
? 操作便捷:將兩表拖拽至配置區,通過連線和雙擊,配置連接關系,簡單幾步就能實現表與表之間的連接和交集。
02 缺失值處理
常用場景
由于信息缺失,致使一部分屬性值空缺出來,在實際的業務場景中,一般有機械和人為兩種原因會導致數據存在空值:
1)機械原因:數據存儲的失敗、存儲器損壞、機械故障導致某段時間數據未能收集(對于定時數據采集而言);
2)人為因素:主觀失誤、歷史局限、有意隱瞞。如,在市場調查中被訪人拒絕透露相關問題的答案,或者回答的問題是無效的,數據錄入人員失誤漏錄了數據。
Tempo機器學習平臺可根據不同類型的數據,使用不同的處理方法填補缺失值,同時也支持批量修改操作:
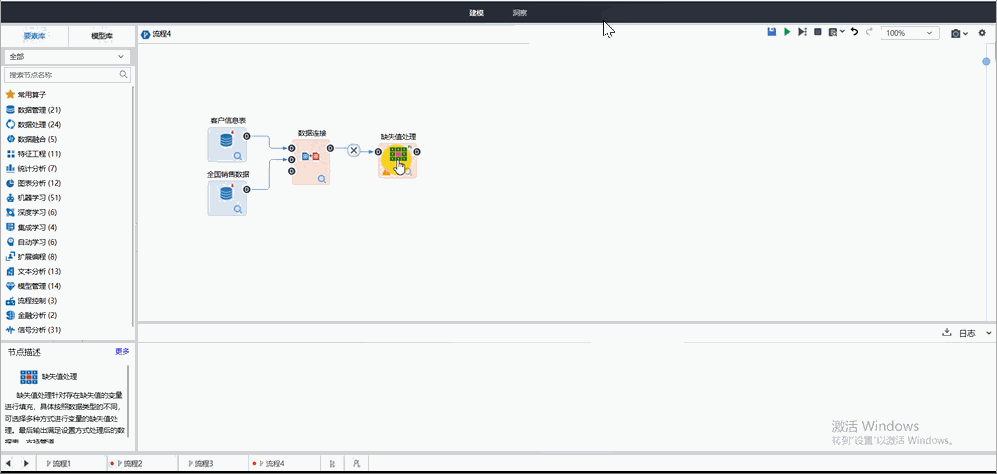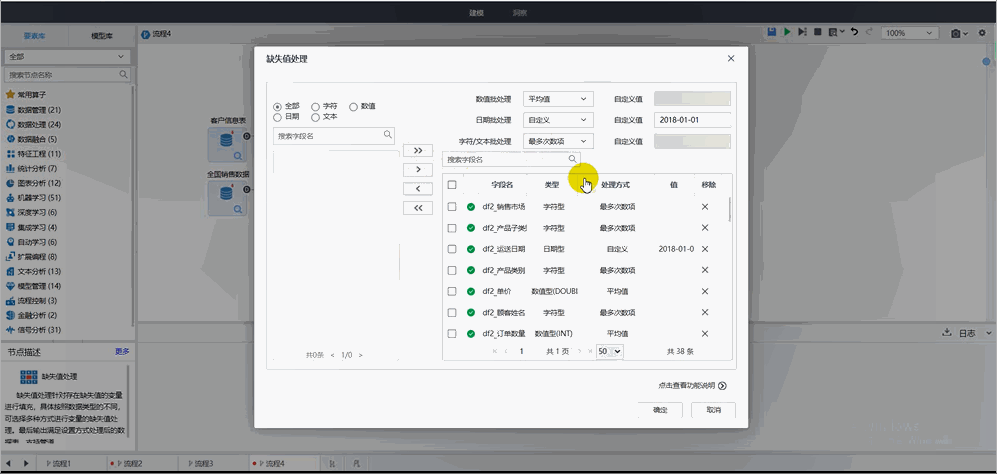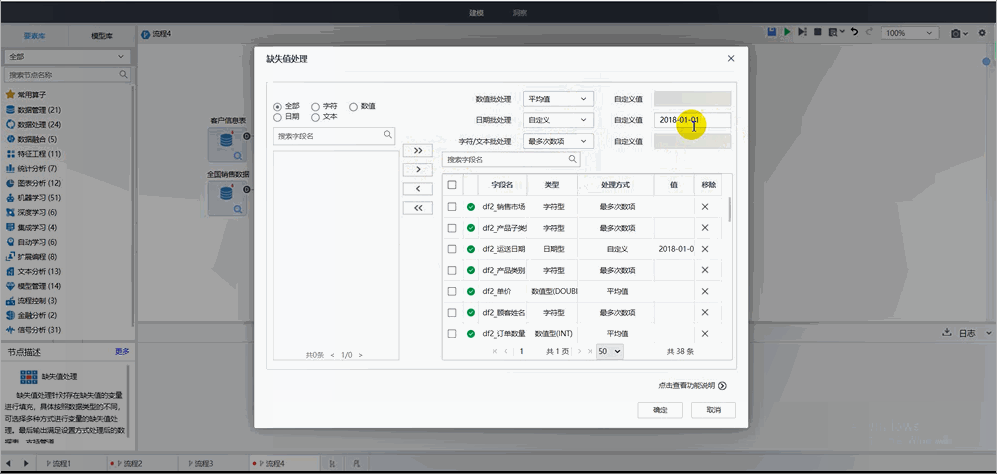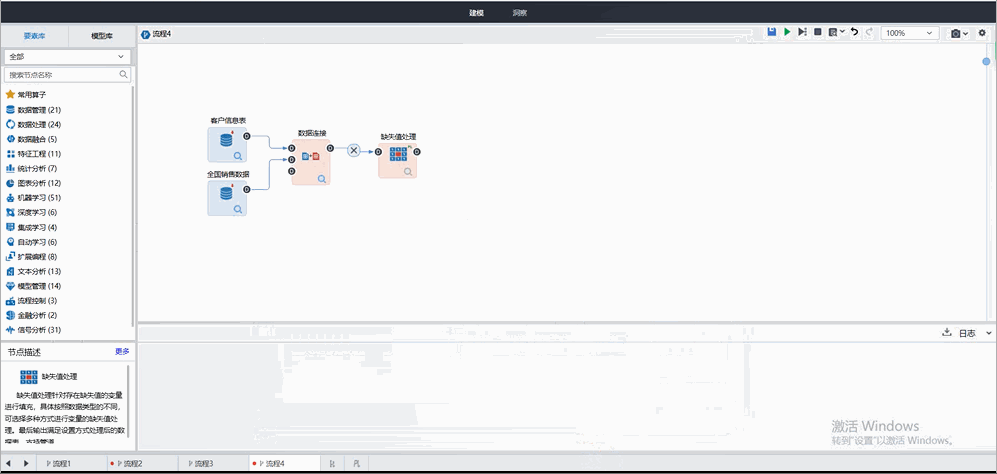
? 數值型處理:針對數值型提供最小值、最大值、平均值、中位數和自定義等方式的缺失值處理;
? 日期型處理:針對日期型提供自定義方式的缺失值處理。支持用戶自己設置一個特定的日期值賦給缺失的單元格;
? 字符型/文本型處理:針對字符型及文本型提供最多次數項、最少次數項和自定義等方式的缺失值處理。
03 數據去重
常用場景
由于某些原因,致使一部分數據被重復記錄,為了節省存儲和計算資源,在實際的分析過程中,只保留有意義的數據,進行后續分析,通過數據去重消除冗余數據。
造成重復值的原因大多是因為采集時多次采集數據,或者在數據合并時再次合并數據,比如問卷填寫時用戶多次填寫,可根據用戶名只保留最后一次填寫的數據,通過去重避免數據沖突。
Tempo機器學習平臺內置了多種策略,可以幫助用戶在使用過程中,根據不同情況進行數據的去重處理。
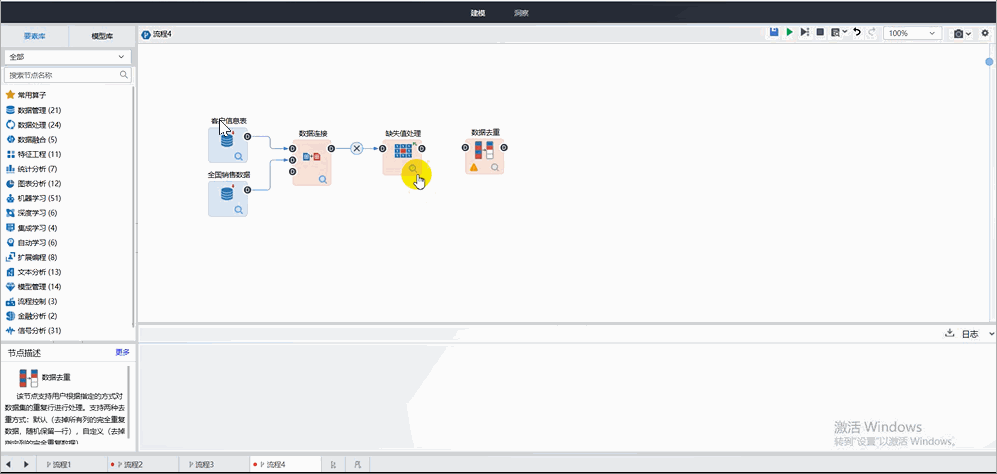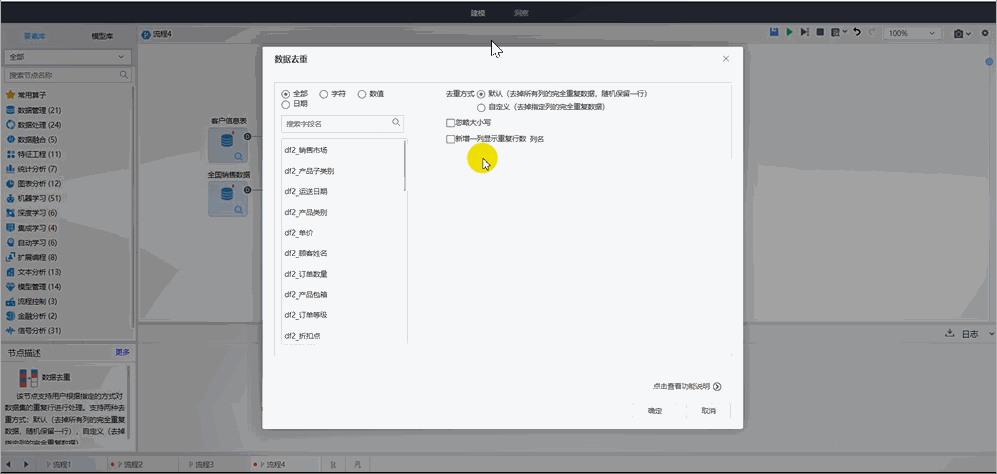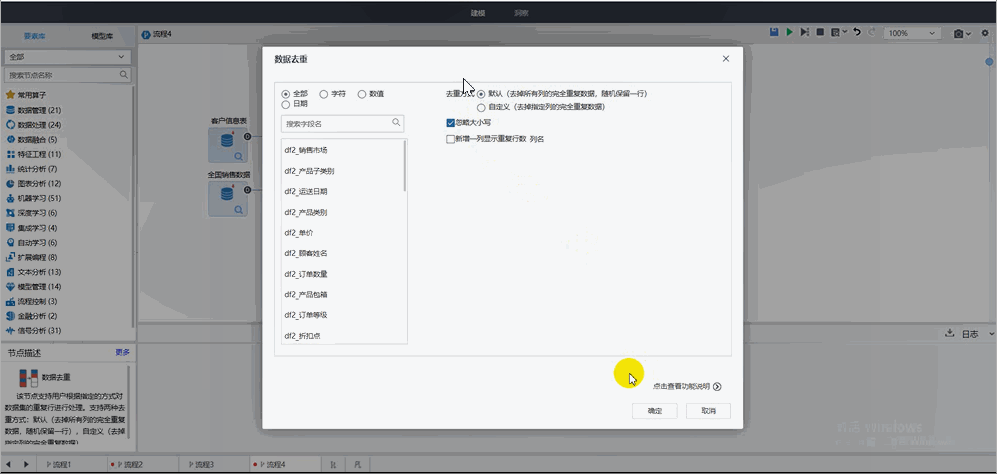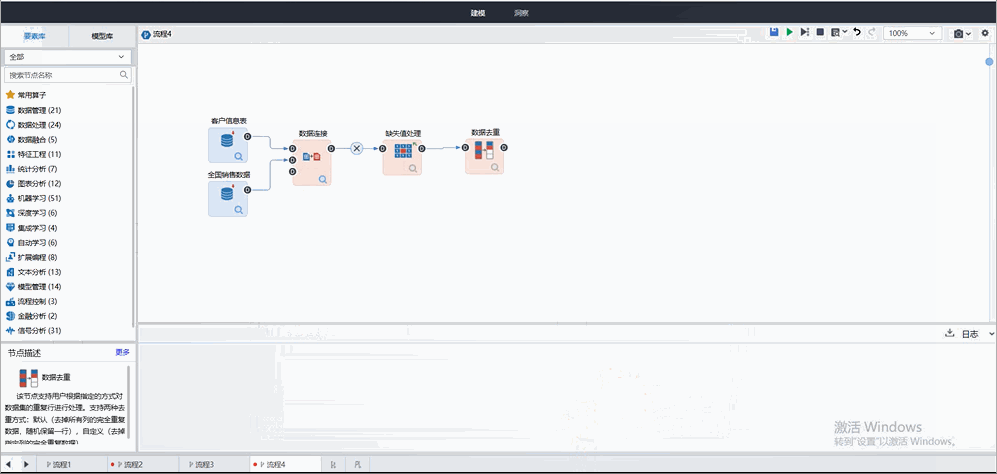
? 默認方式:去掉所有列的完全重復數據,隨機保留一行;
? 自定義方式:去掉指定列的完全重復數據。
04 屬性變換
使用場景
在實際業務中,需要對業務進行細化分類、數據縮放、空值替換、類型轉換等情況。
Tempo機器學習平臺可支持數值型屬性變換、字符型屬性變換和日期型屬性變換:
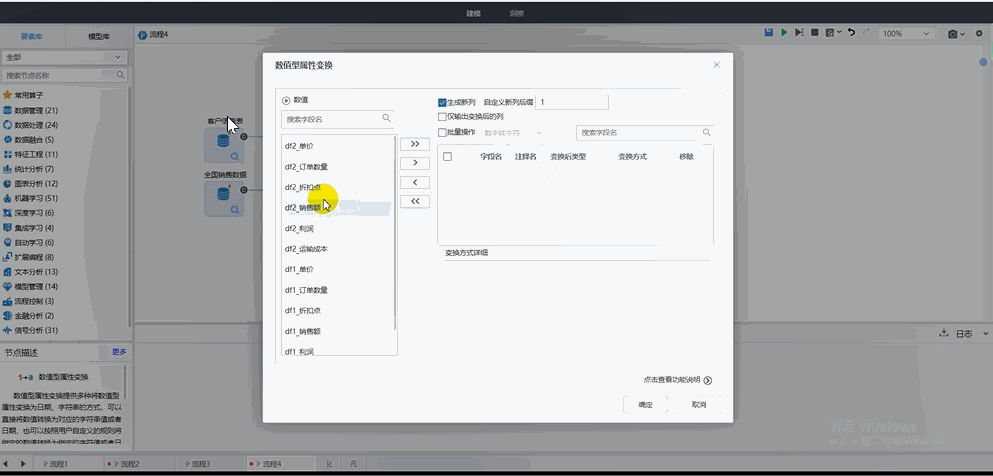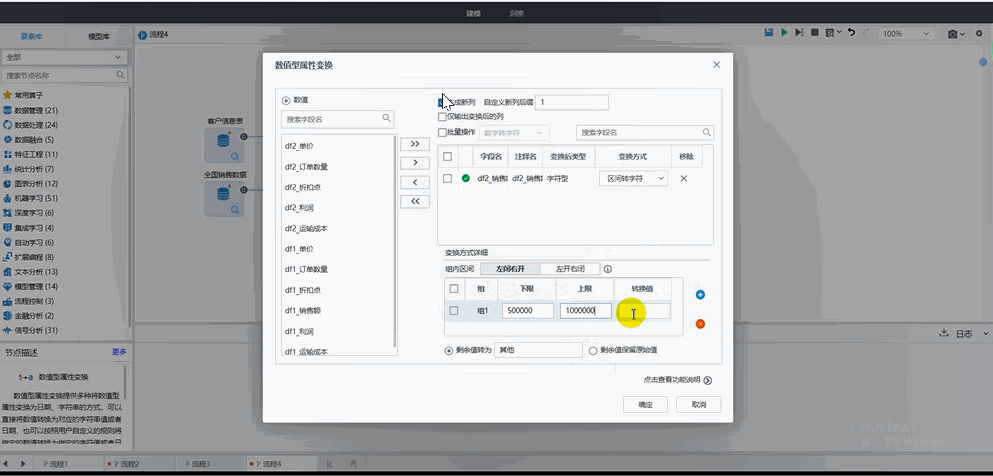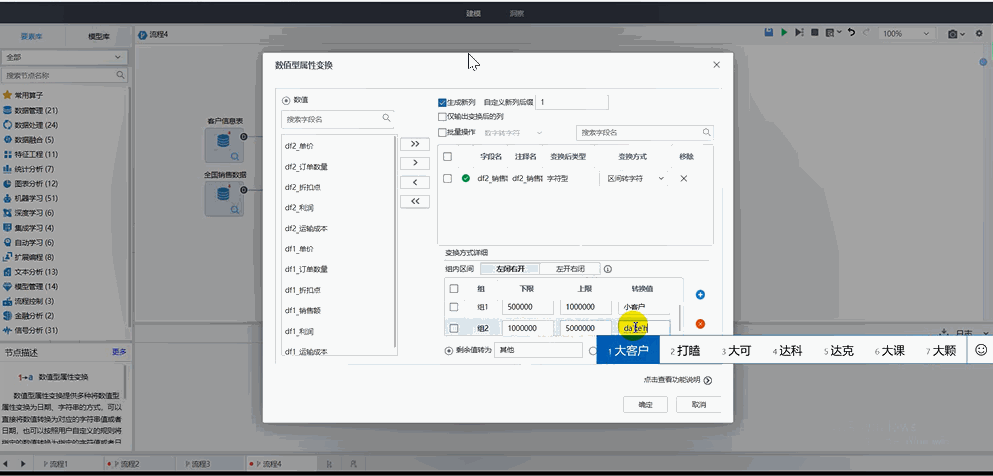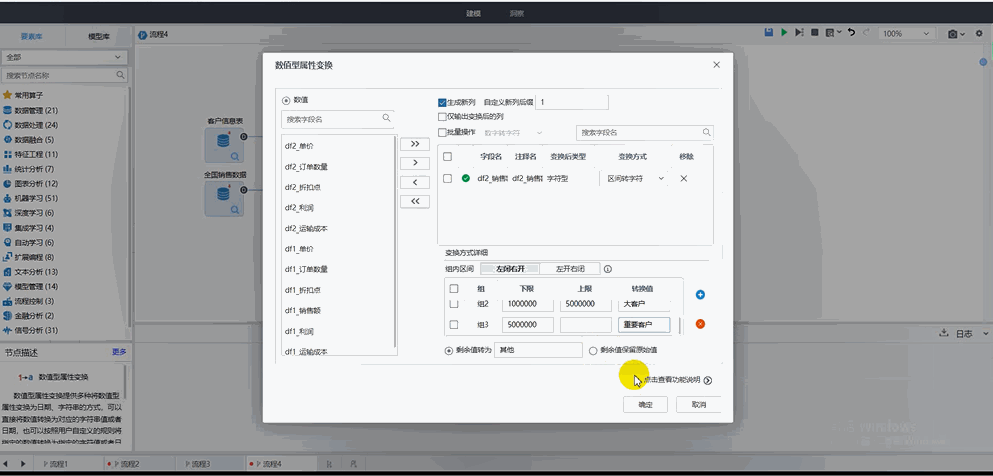
? 數字轉字符:對于數值型屬性變換,可以將數值型數據通過不同的變換方式進行轉換;
? 區間轉字符:用于設置用戶自定義的日期區間轉字符的規則,選擇組內區間,設置日期區間的上下限和轉換值。支持剩余值轉化為其他值或剩余值保留原始值;
? 其他轉換方式:平臺還存在數字轉字符、數字轉日期、平方、平方根、對數、空值轉換、非空值轉換、四舍五入、轉LONG/DOUBLE/FLOAT/INT(四舍五入)/INT(向下取整)、單位轉換等變換方式。
Tempo機器學習平臺支持多種數據預處理方法,能快速實現數據清理、集成、變換、歸約等數據預處理操作,涵蓋了行、列、高級、表級的數據處理方法和多種特征工程方法,能滿足90%以上數據預處理需求,幫助用戶高效完成多源數據的處理、分析,為后續的數據挖掘和分析打下良好的基礎。
圖片
對數據的快速洞察,已成為眾多企業的核心訴求之一。而數據預處理的質量則直接決定了后續建模與分析的成果,通過Tempo AI靈活多樣的數據預處理手段,不僅大大提升了數據清洗的質量,為后續構建模型提供精準的數據,還能有效降低難度,為數據分析師帶來更為便捷的操作,也讓業務人員擁有數據分析的新方式和能力。
Tempo機器學習平臺除了有高效的數據預處理能力,還提供了從數據接入、數據探索、模型構建、模型評估、模型管理、模型部署到最終的工程化應用的全流程“端對端”解決方案。通過多模態多場景智能建模,助力 AI 時代的數據化運營,讓企業輕松開展數據分析,快速洞察數據價值,賦能數字化轉型升級。
全國服務電話:
企業郵箱:tempo@meritdata.com.cn
地址:中國西安 ? 雁塔區西三環天谷八路軟件新城國家電子商務示范基地六層


 陜公網安備 61019002000171號
陜公網安備 61019002000171號



